Chapter 19
Scalable Deep Learning and Distributed Training
"Scalability isn’t just about handling more data or training bigger models; it’s about building systems that grow with the problem and continue to perform as the world changes." — Jeff Dean
Chapter 19 of DLVR provides an in-depth exploration of Scalable Deep Learning and Distributed Training, focusing on the efficient training of deep learning models across multiple processors or machines using Rust. The chapter begins with an introduction to the fundamental concepts of scalability in deep learning, emphasizing the importance of handling large datasets and models as they continue to grow. It discusses the advantages Rust offers in this domain, such as performance, concurrency, and memory safety. The chapter then delves into the challenges of scaling deep learning models, including communication overhead, load balancing, and fault tolerance, and explores strategies like data parallelism and model parallelism for distributed training. Practical guidance is provided on setting up a Rust environment for scalable deep learning, implementing parallelized training loops, and experimenting with batch sizes and gradient accumulation. The chapter further examines data parallelism and model parallelism, offering insights into their trade-offs, synchronization strategies, and practical implementations in Rust. Additionally, it covers distributed training frameworks and tools, highlighting orchestration with Kubernetes and Docker, and the integration of Rust with frameworks like Horovod. Finally, advanced topics such as federated learning, hyperparameter tuning at scale, and the use of specialized hardware like TPUs are explored, with practical examples of implementing these techniques in Rust for scalable and efficient deep learning.
19.1. Introduction to Scalable Deep Learning
Scalable deep learning is centered on distributing computational workloads across multiple resources to enhance training efficiency. This is critical as datasets and model architectures grow in size and complexity. In deep learning, the training process involves minimizing a loss function $L(\theta)$ over a dataset $D$, where the model parameters $\theta$ are updated iteratively using gradient descent. The challenge arises when datasets are too large to compute gradients efficiently in one go, prompting the use of mini-batch gradient descent. By splitting the dataset into smaller batches, we approximate the gradient of the loss function, updating the model iteratively with the gradient computed over each batch.
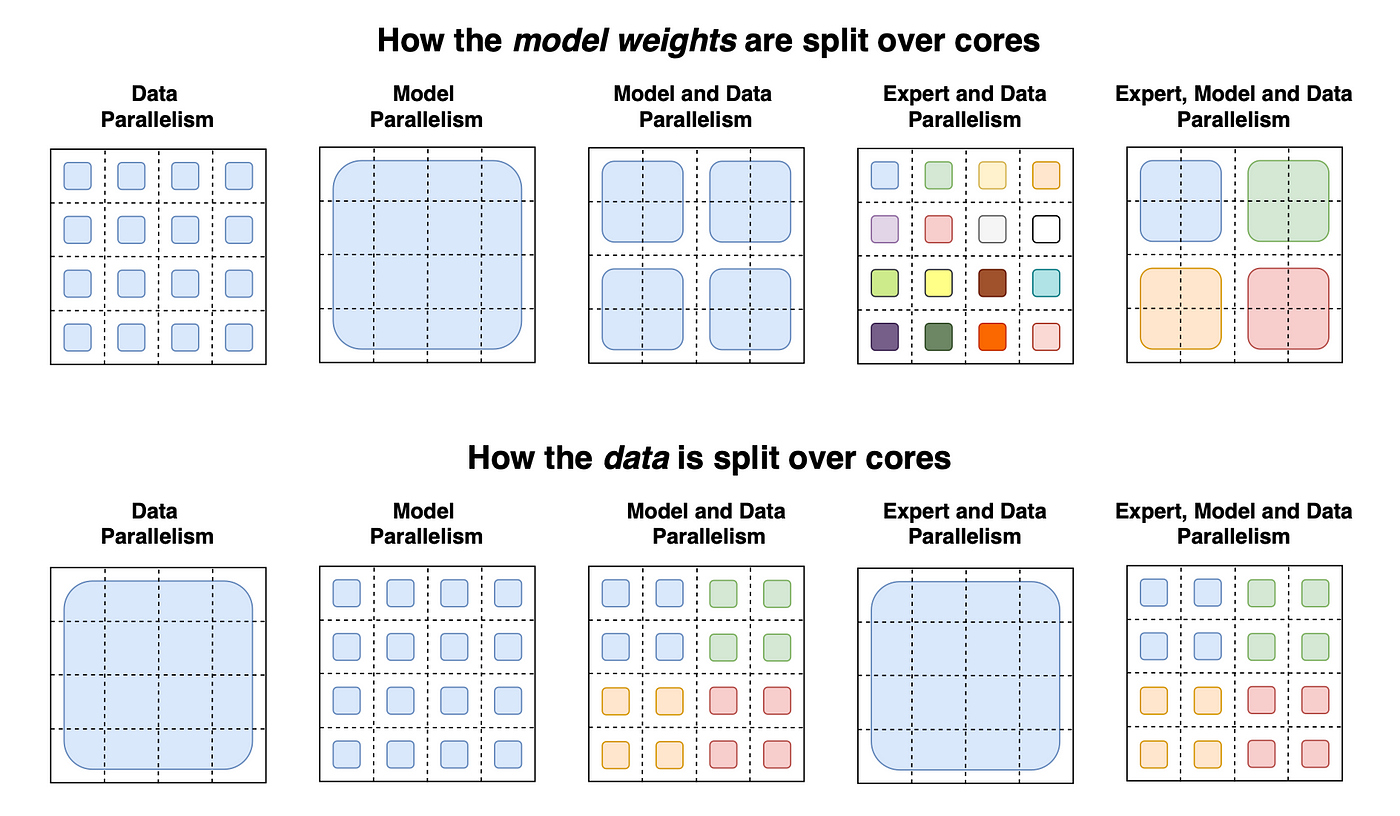
Figure 1: Model and data parallelism concepts for scalable deep learning.
For large-scale deep learning tasks, distributing the data and model parameters across multiple devices, such as CPUs and GPUs, becomes crucial. There are two key strategies for scaling deep learning: data parallelism and model parallelism. In data parallelism, the dataset is split into smaller subsets, and each subset is processed independently on a different device. Gradients are calculated separately on each subset and aggregated across all devices to update the model parameters. This method is useful for large datasets. Model parallelism, on the other hand, involves splitting the model itself across multiple devices, with each device computing gradients for a portion of the model. This approach is essential for models that are too large to fit in the memory of a single device.
However, scaling deep learning efficiently involves more than just dividing data and models. Communication overhead between devices can become a bottleneck as gradients need to be synchronized across multiple devices, often requiring advanced techniques like ring-allreduce to minimize delays. Load balancing ensures that each device has an equal workload, preventing some devices from becoming bottlenecks and stalling overall progress. Moreover, as the scale of computation increases, fault tolerance becomes important since hardware failures or other issues can interrupt the training process. Scalable systems must be designed to be resilient to such failures to ensure that training results are not compromised.
In industrial applications, the need for scalability is especially evident in the development and deployment of large models such as GPT-3, which contains billions of parameters. These models require distributed training strategies across clusters of GPUs to be trained within a reasonable time frame. For instance, companies like Google, OpenAI, and NVIDIA have implemented distributed training across hundreds or even thousands of GPUs to reduce training time from months to days. Scalability is not only important during training but also during inference, where large models often need to handle real-time requests with minimal latency. This requires the ability to distribute inference tasks across multiple machines to maintain performance in production environments.
Rust offers several unique advantages for scalable deep learning, particularly in terms of performance, concurrency, and memory safety. Rust’s ownership and borrowing system ensures that memory is managed efficiently without runtime garbage collection, making it ideal for handling large datasets and models in a performance-critical environment. Additionally, Rust’s concurrency model, supported by the Rayon and Tokio crates, allows for efficient parallel processing, enabling Rust to scale tasks across multiple threads or machines effectively. These features make Rust well-suited for building distributed systems where safety, performance, and efficiency are crucial.
The following Rust code demonstrates a scalable deep learning training loop that leverages parallel processing. The rayon crate is used to divide the dataset into mini-batches, which are processed in parallel across multiple threads. The tch-rs crate, a Rust binding for PyTorch, is used for tensor operations and model training.
use rayon::prelude::*;
use tch::{Tensor, nn, nn::ModuleT, nn::OptimizerConfig, Device};
fn train_parallel(model: &nn::SequentialT, dataset: &[Tensor], optimizer: &mut nn::Optimizer<impl nn::OptimizerConfig>, epochs: usize) {
let device = Device::cuda_if_available();
for epoch in 0..epochs {
dataset.par_chunks(64) // Split the dataset into chunks for parallel processing
.for_each(|batch| {
let inputs = Tensor::cat(&batch[..], 0).to_device(device);
let targets = Tensor::cat(&batch[..], 0).to_device(device);
let loss = model.forward_t(&inputs, true).mse_loss(&targets, tch::Reduction::Mean);
optimizer.backward_step(&loss);
});
println!("Epoch {} completed", epoch);
}
}
This implementation splits the dataset into mini-batches and processes them concurrently using Rayon’s par_chunks method, enabling efficient parallel computation. The tch-rs crate is used for tensor operations and neural network training, utilizing GPU acceleration where available. By using Rust’s concurrency model, the training process is highly efficient and scalable across multiple devices.
Key factors in scalable deep learning include batch size and gradient accumulation. Using larger batch sizes allows better utilization of GPUs but may require gradient accumulation when memory is limited. Gradient accumulation involves accumulating gradients over multiple mini-batches before performing a parameter update, which helps maintain stable learning dynamics even with larger batch sizes. These techniques ensure that large datasets and models can be trained efficiently without sacrificing accuracy or performance.
In conclusion, scalable deep learning is critical as datasets and models grow larger, and Rust’s performance, concurrency, and memory safety features make it well-suited for handling these demands. By leveraging libraries like tch-rs and rayon, developers can build scalable and efficient deep learning systems that are capable of distributing both data and model computations across multiple devices. This enables faster training times and ensures that deep learning models can be deployed effectively in both research and industry settings.
19.2. Data Parallelism in Deep Learning
Data parallelism is a widely used technique in deep learning that focuses on splitting a large dataset across multiple processors, GPUs, or machines to train multiple copies of the same model simultaneously. Each processor computes the gradients for its subset of data, and these gradients are then aggregated to update the shared model parameters.
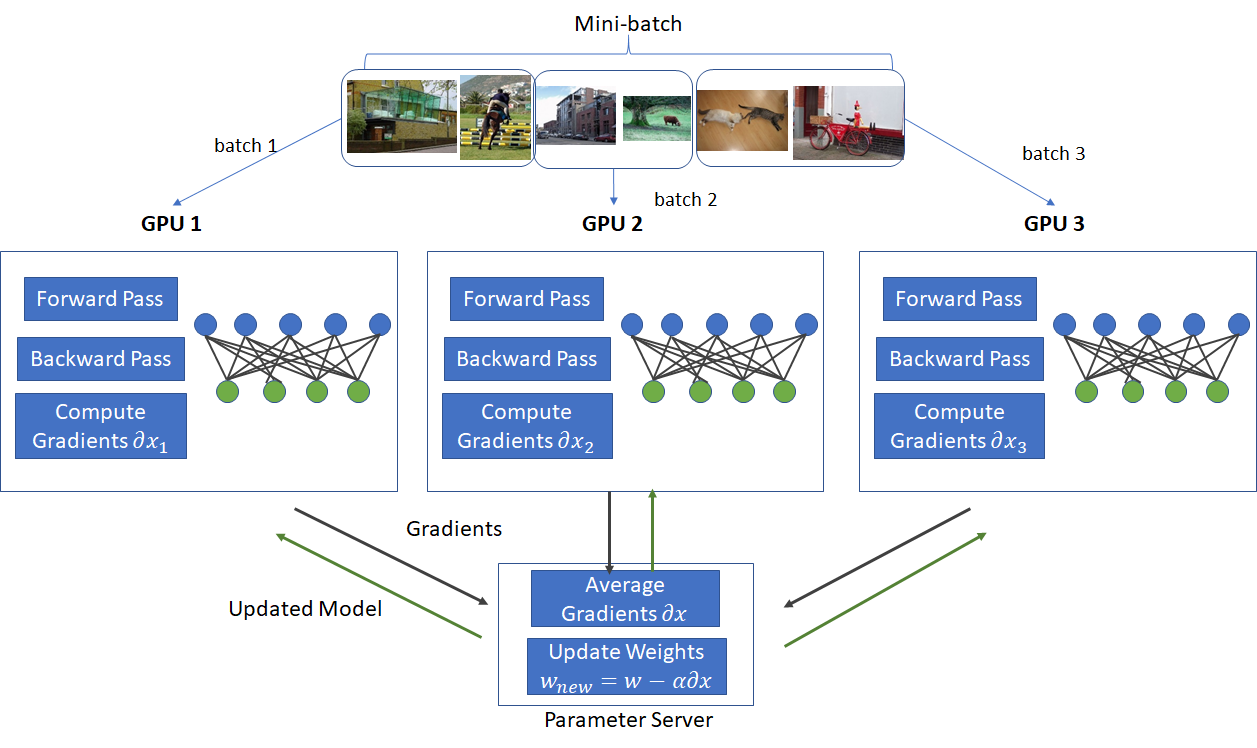
Figure 2: Data parallelism concept of scalable deep learning.
Mathematically, assume we have a dataset $D = \{x_1, x_2, \dots, x_N\}$ with $N$ total data points, and we split this dataset into $P$ partitions, one for each processor, such that each partition $D_i \subset D$ has approximately $\frac{N}{P}$ data points. For each partition $D_i$, the processor computes a local gradient $\nabla_{\theta} L_i(\theta)$, where $L_i(\theta)$ represents the loss function for the subset of data $D_i$.
The local gradients are then averaged across all $P$ processors to obtain the global gradient:
$$\nabla_{\theta} L(\theta) = \frac{1}{P} \sum_{i=1}^{P} \nabla_{\theta} L_i(\theta)$$
This global gradient is used to update the model parameters:
$$\theta^{(t+1)} = \theta^{(t)} - \eta \nabla_{\theta} L(\theta)$$
This approach is known as synchronous training, where all processors wait for each other to compute gradients before updating the model parameters. In contrast, asynchronous training allows each processor to update the model parameters independently, leading to potentially faster convergence but at the cost of possible stale gradients, which could affect the accuracy of the model.
The challenge with synchronous training is the need for efficient communication to aggregate gradients across processors. Common communication strategies include:
Parameter Servers: A centralized server collects gradients from all processors, averages them, and sends the updated parameters back to the processors. This introduces a potential communication bottleneck at the parameter server.
Collective Communication: Techniques like All-Reduce, which avoids the bottleneck by distributing the task of gradient aggregation across all processors, can achieve better scalability. In All-Reduce, each processor exchanges gradients with its peers in a ring-like fashion to collectively compute the global gradient.
The primary trade-off in data parallelism lies between synchronous and asynchronous training:
Synchronous Training: Offers consistent and reliable updates because all processors update the model using the same global gradient. However, the speed of training is limited by the slowest processor, often referred to as the straggler problem. If one processor is slower due to hardware or network issues, it can delay the entire system.
Asynchronous Training: Allows each processor to update the model independently, reducing the training time by eliminating the need to wait for slow processors. However, asynchronous updates can lead to stale gradients—gradients that are calculated based on outdated model parameters—causing issues in convergence and stability.
Another important consideration is gradient averaging. During data-parallel training, the gradients calculated on different subsets of data are averaged to update the model. The accuracy and efficiency of this gradient averaging process depend on the communication strategy and the consistency of updates across processors.
Load balancing is crucial to avoid some processors being overburdened while others remain idle. Proper distribution of data across processors, along with techniques for dynamic adjustment, ensures that all workers are utilized efficiently, maximizing parallelism.
In industry, data parallelism is a fundamental technique for training large-scale deep learning models. Major companies like Google, Facebook, and Nvidia employ data-parallel strategies to accelerate training on vast datasets, such as image datasets (e.g., ImageNet) or large text corpora for language models (e.g., BERT and GPT). Frameworks like TensorFlow and PyTorch, widely used in these organizations, provide built-in support for data-parallelism across multiple GPUs and even distributed clusters.
For example, Facebook's "ZeRO" technique (used in the DeepSpeed library) is an optimization of data parallelism that reduces memory usage and enables the training of extremely large models across hundreds of GPUs. Similarly, the Horovod library, built by Uber, leverages collective communication methods like All-Reduce to efficiently aggregate gradients in distributed training environments.
Rust offers several advantages when implementing data-parallel deep learning systems, including its concurrency model, memory safety, and performance. With libraries such as tch-rs for deep learning and rayon for parallel computation, Rust allows developers to build scalable and safe data-parallel systems with minimal overhead.
Here is an example of how to implement data parallelism in Rust using tch-rs and rayon to parallelize the training across multiple devices:
use rayon::prelude::*;
use tch::{nn, nn::OptimizerConfig, Tensor, Device};
fn train_data_parallel(model: &nn::SequentialT, dataset: &[Tensor], optimizer: &mut nn::Optimizer<impl nn::OptimizerConfig>, devices: &[Device], epochs: usize) {
let data_chunks = dataset.chunks(devices.len()); // Split dataset into chunks, one for each device
for epoch in 0..epochs {
data_chunks.enumerate().par_bridge().for_each(|(idx, chunk)| {
let device = devices[idx]; // Assign each chunk to a different device
let inputs = Tensor::cat(&chunk[..], 0).to_device(device);
let output = model.forward_t(&inputs, true);
let loss = output.mse_loss(&inputs, tch::Reduction::Mean);
optimizer.backward_step(&loss);
});
// Aggregate gradients from each device using All-Reduce or custom aggregation strategy
aggregate_gradients(model, devices);
println!("Epoch {} completed", epoch);
}
}
fn aggregate_gradients(model: &nn::SequentialT, devices: &[Device]) {
// Example: Use an All-Reduce-like method to synchronize gradients across devices
let model_params = model.parameters();
for param in model_params {
let mut summed_param = Tensor::zeros_like(¶m);
devices.iter().for_each(|&device| {
let param_on_device = param.to_device(device);
summed_param += ¶m_on_device;
});
let avg_param = summed_param / (devices.len() as f64);
param.copy_(&avg_param); // Update the parameter with the averaged gradient
}
}
In this example, the dataset is divided into chunks using chunks(), where each chunk is processed on a different device (GPU or CPU). The rayon crate is employed to run the training loop in parallel across multiple devices. After each training step, the gradients are aggregated using an All-Reduce-like strategy, which ensures that all devices have the same updated model parameters.
This approach demonstrates synchronous training, where gradient updates are synchronized after each batch. However, it can be adapted to asynchronous training by removing the gradient synchronization step and allowing each device to update the model independently. Asynchronous training can speed up training in environments where processors have varying performance but may introduce gradient staleness.
Parameter Servers and All-Reduce are two primary strategies for communication in distributed data parallelism. In the example above, a simple All-Reduce strategy is simulated by averaging the parameters across devices. This strategy avoids the bottleneck of a central parameter server and distributes the communication workload evenly across devices.
In practical settings, more efficient collective communication algorithms (e.g., NCCL in GPU environments) can be integrated into the system to handle gradient aggregation at scale. Implementing these communication strategies efficiently in Rust is feasible, thanks to its low-level control over memory and concurrency, ensuring high performance and minimal overhead.
Data parallelism is a powerful strategy for scaling deep learning, allowing training on large datasets by distributing computations across multiple devices or machines. Rust’s performance, concurrency features, and memory safety make it an ideal language for implementing scalable deep learning systems. By leveraging libraries like tch-rs for tensor computation and rayon for parallelism, developers can efficiently implement data-parallel training with gradient synchronization strategies. As the deep learning industry continues to push the boundaries of scale, data parallelism will remain a critical technique, and Rust’s ecosystem is well-positioned to support this growth.
19.3. Model Parallelism in Deep Learning
Model parallelism is a technique that distributes the computation of a deep learning model across multiple processors or devices. This approach is particularly useful when models are too large to fit into the memory of a single processor, such as massive transformer models like GPT-3, which can have billions of parameters.
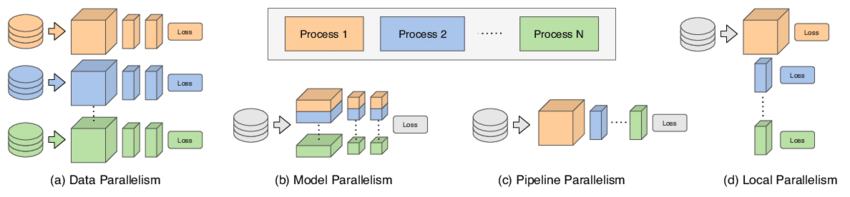
Figure 3: Various parallelism methods for scalable deep learning.
In contrast to data parallelism, where the model is replicated across devices and data is split, model parallelism splits the model itself. Assume a model with parameters $\theta = \{ \theta_1, \theta_2, ..., \theta_n \}$, where each subset $\theta_i$ corresponds to a part of the model, such as different layers in a neural network. These subsets are distributed across $P$ processors, and each processor computes the forward and backward passes for the parameters it holds.
Given an input $x$, the forward pass is performed in stages:
$$h_1 = f_1(x, \theta_1) \quad (on\ processor\ 1)$$
$$h_2 = f_2(h_1, \theta_2) \quad (on\ processor\ 2)$$
$$\vdots$$
$$y = f_n(h_{n-1}, \theta_n) \quad (on\ processor\ n)$$
During backpropagation, the gradient calculation also follows this chain, with each processor computing the gradients for its part of the model and passing the intermediate gradients to the previous stage:
$$\nabla_{\theta_i} L = \frac{\partial L}{\partial \theta_i} = \frac{\partial L}{\partial h_i} \cdot \frac{\partial h_i}{\partial \theta_i}$$
The challenge is ensuring that communication between processors is efficient, as each processor must send and receive intermediate activations and gradients during forward and backward passes. This introduces communication overhead, particularly when large volumes of data need to be transferred between devices.
Model parallelism can be applied in several forms, depending on how the model is split and executed across devices. One specific form is pipeline parallelism, where different layers of a model are assigned to different processors and processed in a sequential pipeline. For example, in a deep neural network, layer 1 might be processed on GPU 1, layer 2 on GPU 2, and so on.
A key concept in pipeline parallelism is the use of micro-batches, which allow different parts of the model to be processed in parallel, even though the overall model is sequential. This helps reduce idle time on processors and improves utilization. However, there is a trade-off: the more micro-batches we process concurrently, the more we introduce pipeline bubbles, which represent idle times when one part of the model waits for data from another part.
Checkpointing and recomputation are essential strategies in model parallelism to manage memory usage. Since large models often exceed memory limits, some intermediate activations can be discarded during forward passes and recomputed during the backward pass. This reduces memory consumption but introduces some additional computation overhead.
In industry, model parallelism is critical for training extremely large models that cannot be handled with data parallelism alone. For example, transformer models used for natural language processing (NLP) tasks, such as BERT or GPT, often require model parallelism because their parameters are too large to fit in the memory of a single GPU. Companies like OpenAI, Google, and Microsoft use model parallelism in their large-scale models for applications such as language generation, translation, and recommendation systems.
A notable example is pipeline parallelism used in models like GPT-3, where different layers of the transformer architecture are split across multiple GPUs. This enables faster training and inference by utilizing multiple devices efficiently. Additionally, in reinforcement learning applications where models interact with environments in real-time, model parallelism ensures that massive models can still be trained in a reasonable amount of time without exceeding memory limits.
The choice between data parallelism and model parallelism depends on the size of the model and the available hardware resources. Data parallelism is easier to implement and scales well for moderately large models, but it becomes impractical when the model itself is too large to fit into memory. In such cases, model parallelism becomes necessary. However, model parallelism introduces its own challenges:
Communication Overhead: Model parallelism requires frequent communication between devices, especially during forward and backward passes. Efficient communication strategies (e.g., collective communication, ring-allreduce) are essential to minimize delays.
Load Balancing: Ensuring that all processors have equal computational loads is more challenging in model parallelism. Some parts of the model may require more computation than others, leading to idle times for certain processors.
Fault Tolerance: Since model parallelism distributes different parts of the model across devices, the failure of a single device can disrupt the entire training process. Robust checkpointing strategies are critical to ensure fault tolerance.
Rust's concurrency features and memory safety make it an excellent choice for implementing model parallelism, particularly when combined with the tch-rs crate, which interfaces with PyTorch. The following example demonstrates how to implement a simple model parallelism system in Rust, where different layers of a model are split across multiple devices:
use tch::{nn, nn::ModuleT, Tensor, Device};
fn model_parallelism_example(vs: &nn::VarStore, devices: &[Device]) {
let layer1 = nn::linear(vs.root(), 784, 512, Default::default());
let layer2 = nn::linear(vs.root(), 512, 256, Default::default());
let layer3 = nn::linear(vs.root(), 256, 10, Default::default());
let device1 = devices[0];
let device2 = devices[1];
// Example input batch
let input = Tensor::randn(&[64, 784], (tch::Kind::Float, device1));
// Forward pass: Layer 1 on device1, Layer 2 on device2, Layer 3 back on device1
let h1 = layer1.forward_t(&input, true).to_device(device2);
let h2 = layer2.forward_t(&h1, true).to_device(device1);
let output = layer3.forward_t(&h2, true);
println!("Output: {:?}", output);
}
fn main() {
let vs = nn::VarStore::new(Device::cuda_if_available());
let devices = vec![Device::Cuda(0), Device::Cuda(1)]; // Correctly capitalized "Cuda"
model_parallelism_example(&vs, &devices);
}
In this implementation, model parallelism is demonstrated by distributing different layers of the neural network across multiple GPUs. Layer 1 is assigned to GPU 0 (device1), Layer 2 to GPU 1 (device2), and Layer 3 is placed back on GPU 0. As data passes through the network, it moves between devices as needed to ensure that each layer performs its computation on the assigned GPU. The to_device method is utilized to transfer the intermediate activations and gradients between GPUs, simulating the communication and synchronization that would be required in a model parallelism setup. This allows larger models to be trained even when a single GPU does not have enough memory to hold the entire model, distributing the computational workload across multiple GPUs.
This basic example demonstrates how parts of a neural network can be distributed across different devices. However, in practice, more advanced techniques like pipeline parallelism and gradient checkpointing would be employed for larger models. By splitting the model into layers processed on different GPUs, we can efficiently train models that exceed the memory limits of a single device.
Model parallelism is essential when dealing with very large models that do not fit into the memory of a single processor or GPU. It distributes the model’s parameters across multiple devices, allowing for efficient training by splitting the computational load. Rust’s strong concurrency model and memory safety, combined with libraries like tch-rs, provide the tools to implement model parallelism in a scalable and efficient manner. From pipeline parallelism to advanced gradient checkpointing techniques, Rust allows developers to experiment with model parallelism strategies that are critical in both scientific research and large-scale industry applications.
19.4. Distributed Training Frameworks and Tools
In distributed training, the key objective is to distribute both data and computation across multiple machines (or nodes) to accelerate the training of large deep learning models. The distributed training process can be represented mathematically as follows:
Let $L(\theta; x, y)$ represent the loss function of a model parameterized by $\theta$, with input data $x$ and labels $y$. In a distributed setting, this loss function is computed independently on multiple nodes, each processing a subset of the data. Given a dataset $D$, it is partitioned into $N$ subsets $D_i$, where each subset $D_i \subset D$ is assigned to a different worker node.
The gradient of the loss function with respect to $\theta$, calculated on the $i$-th worker node, is:
$$\nabla_{\theta} L_i(\theta) = \frac{1}{|D_i|} \sum_{(x,y) \in D_i} \nabla_{\theta} L(\theta; x, y)$$
In a synchronous distributed training setup, the gradients computed by all nodes are aggregated to form a global gradient:
$$\nabla_{\theta} L(\theta) = \frac{1}{N} \sum_{i=1}^{N} \nabla_{\theta} L_i(\theta)$$
This global gradient is then used to update the model parameters:
$$\theta^{(t+1)} = \theta^{(t)} - \eta \nabla_{\theta} L(\theta)$$
The challenge is ensuring that all nodes communicate efficiently to aggregate gradients without causing delays. In an asynchronous setup, each node updates the parameters independently, which may result in faster training but introduces the risk of using stale gradients, potentially affecting model convergence.
Distributed training frameworks are essential for coordinating the complex operations involved in training across multiple machines. These frameworks typically handle communication between nodes, synchronization of model updates, and management of resources such as GPUs and memory. In the Rust ecosystem, distributed training tools are still developing compared to more mature frameworks like TensorFlow and PyTorch, but powerful tools are available for building distributed systems.
Orchestration Tools: Tools like Kubernetes and Docker play a vital role in managing distributed training environments. These tools provide infrastructure to deploy, scale, and monitor distributed applications efficiently. Kubernetes enables the dynamic allocation of resources across multiple nodes in a cluster, while Docker ensures that applications run in isolated, containerized environments, making them portable and reproducible.
Distributed File Systems: Training large models on distributed clusters often requires distributed file systems such as HDFS (Hadoop Distributed File System) or Ceph. These systems ensure that data is available across multiple nodes for parallel processing and that checkpoints and logs are stored reliably.
Fault Tolerance and Monitoring: In large-scale distributed training, hardware failures or network issues are common. Distributed training frameworks must be able to handle such failures gracefully, often through checkpointing (saving model states at regular intervals) and logging. Tools such as Prometheus and Grafana can be used to monitor training jobs, track resource usage, and ensure the reliability of the system.
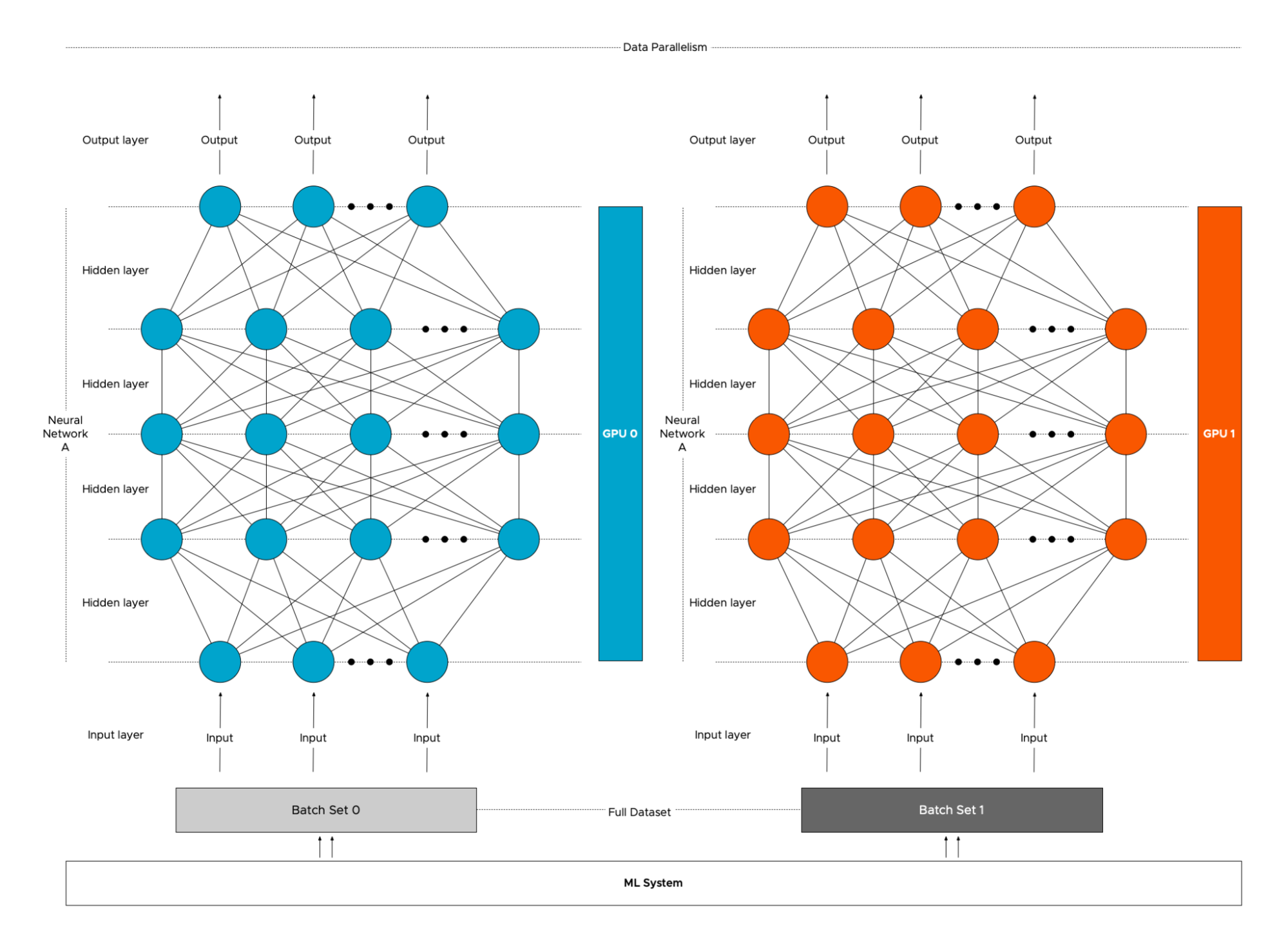
Figure 4: Illustration of distributed training for deep learning.
Although Rust’s ecosystem for distributed deep learning frameworks is not as mature as that of TensorFlow or PyTorch, some tools are emerging. For example, Horovod, which is widely used in TensorFlow and PyTorch for distributed training, can also be integrated with Rust via the tch-rs crate. Horovod simplifies distributed training by abstracting away the communication between nodes and supporting both data parallelism and model parallelism across multiple GPUs.
Another tool that integrates well with Rust for distributed computing is Dask, a parallel computing library that scales across multiple nodes and cores. While Dask is primarily a Python-based tool, Rust can be used to develop high-performance components that can interact with Dask for distributed computations, particularly for data pre-processing or model inference.
Setting up a distributed training environment in Rust involves deploying training jobs across multiple machines or containers, orchestrating the execution, and monitoring the performance. The following steps illustrate how to implement and deploy a simple distributed training job using Rust, Docker, and Kubernetes.
Step 1: Containerizing the Training Job with Docker
First, create a Dockerfile for the Rust training job. This ensures the environment is reproducible and can run across multiple nodes in a cluster:
FROM rust:1.64
# Set the working directory inside the container
WORKDIR /usr/src/app
# Copy the current directory to the container
COPY . .
# Install necessary dependencies
RUN cargo install --path .
# Run the application
CMD ["cargo", "run"]
Step 2: Building and Running the Docker Container
Once the Dockerfile is set up, build the Docker image:
docker build -t rust-distributed-training .
You can then run this container on your local machine or push it to a container registry for deployment on Kubernetes.
Step 3: Deploying on Kubernetes
Kubernetes can be used to orchestrate the deployment of this container across multiple nodes in a cluster. A sample Kubernetes YAML configuration might look like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: rust-training-job
spec:
replicas: 4
template:
metadata:
labels:
app: rust-training-job
spec:
containers:
- name: rust-container
image: rust-distributed-training:latest
ports:
- containerPort: 8080
This configuration deploys four replicas of the Rust container, each running on a separate node in the Kubernetes cluster. Kubernetes handles resource allocation, scaling, and fault tolerance.
Step 4: Implementing Distributed Training Logic in Rust
Here is a basic Rust implementation of distributed gradient aggregation using the MPI (Message Passing Interface) for communication between nodes:
use mpi;
use mpi::traits::*;
use tch::{nn, nn::ModuleT, Tensor};
fn main() {
let universe = mpi::initialize().unwrap();
let world = universe.world();
// Create a simple model
let vs = nn::VarStore::new(tch::Device::cuda_if_available());
let model = nn::seq()
.add(nn::linear(vs.root(), 784, 128, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(vs.root(), 128, 10, Default::default()));
// Dummy input and target
let input = Tensor::randn(&[64, 784], (tch::Kind::Float, tch::Device::cuda_if_available()));
let target = Tensor::randn(&[64, 10], (tch::Kind::Float, tch::Device::cuda_if_available()));
// Forward pass
let output = model.forward_t(&input, true);
let loss = output.mse_loss(&target, tch::Reduction::Mean);
// Compute gradients
loss.backward();
// Get the gradients from all workers
let grads = vs.variables().grad();
// Use MPI to aggregate gradients across all workers
world.all_reduce_into(&grads, &mut Tensor::zeros_like(&grads), mpi::collective::SystemOperation::sum);
println!("Distributed training complete.");
}
In this implementation, the model parameters and gradients are aggregated across multiple nodes using MPI. Each worker node computes the gradient for its subset of data, and MPI’s all_reduce function is used to aggregate these gradients, ensuring synchronized updates to the model.
For reliable distributed training, monitoring tools like Prometheus and Grafana can be integrated to track system metrics such as CPU/GPU usage, memory consumption, and network throughput. These metrics help detect bottlenecks in the distributed system, identify hardware failures, and ensure that the training job progresses efficiently.
Distributed training frameworks and orchestration tools play a critical role in scaling deep learning models across multiple machines and GPUs. Rust, though still developing its ecosystem in this space, offers promising performance and safety features for building distributed training systems. By integrating tools like Docker, Kubernetes, Horovod, and MPI, developers can build scalable and reliable distributed training pipelines using Rust. In industry, such tools are fundamental to handling massive datasets and training large models, and Rust’s concurrency and performance advantages make it a strong candidate for future developments in distributed deep learning.
19.5. Advanced Topics in Scalable Deep Learning
Scalable deep learning covers a broad range of advanced techniques and approaches aimed at training models efficiently across large, distributed systems. This section explores key advanced topics like federated learning, hyperparameter tuning at scale, and the use of specialized hardware like TPUs.
In federated learning, the training process occurs across multiple decentralized devices, where the data remains local, and only the model updates (gradients) are shared with a central server. This approach is crucial when privacy constraints prevent data from being centralized. Mathematically, if we consider $D_i$ as the local dataset on device $i$, each device computes the local gradient $\nabla_{\theta} L_i(\theta)$ for the model parameters $\theta$, where $L_i(\theta)$ is the local loss function.
The central server aggregates the gradients from all participating devices:
$$\theta^{(t+1)} = \theta^{(t)} - \eta \frac{1}{N} \sum_{i=1}^{N} \nabla_{\theta} L_i(\theta)$$
This approach ensures that data $D_i$ never leaves device $i$, thus preserving privacy while still benefiting from distributed training.
Hyperparameter tuning can be formalized as an optimization problem where we seek to find the hyperparameters $\lambda \in \Lambda$ that minimize the model’s validation loss $L_{val}(\theta(\lambda))$:
$$\lambda^* = \arg \min_{\lambda \in \Lambda} L_{val}(\theta(\lambda))λ∗=arg$$
In a distributed setting, this search process is parallelized across multiple nodes, using techniques such as grid search, random search, or Bayesian optimization. Each node evaluates a different combination of hyperparameters, and the results are aggregated to determine the best-performing set of hyperparameters.
In reinforcement learning (RL), scaling across multiple nodes typically involves parallelizing exploration (where agents interact with different environments) and training (where agents learn from their experiences). The objective is to maximize a cumulative reward $R = \sum_t r_t$ over time by adjusting the agent’s policy $\pi$. In distributed RL, multiple agents independently explore the environment and send back experience (state, action, reward, next state tuples) to a central learner, which updates the policy and redistributes the updated parameters to the agents.
Federated Learning: This method enables training on decentralized data while preserving privacy. However, it introduces challenges such as communication overhead and heterogeneous data distributions across devices. Synchronizing model updates across devices without significantly delaying training requires efficient communication strategies, such as asynchronous aggregation or federated averaging.
Hyperparameter Tuning at Scale: Traditional hyperparameter tuning methods are computationally expensive. Scaling these methods in distributed environments reduces time, but coordination among nodes is critical to avoid redundancy in hyperparameter evaluations. Techniques like Bayesian optimization intelligently explore the hyperparameter space by learning from previous evaluations to prioritize the most promising regions.
TPUs and Hardware Accelerators: Specialized hardware like TPUs (Tensor Processing Units) significantly accelerates deep learning workloads by optimizing matrix multiplications and tensor operations. Rust, with its focus on performance and safety, can interface with TPUs and other accelerators through bindings to external libraries like tch-rs or directly via low-level APIs. Integrating Rust with TPUs requires managing data transfer efficiently to prevent bottlenecks.
In industry, federated learning is particularly useful in sectors like healthcare and finance, where data privacy is paramount. For example, hospitals might collaboratively train a model for disease prediction without sharing sensitive patient data. Companies like Google have pioneered federated learning in production environments, particularly for mobile applications like predictive text, where data is spread across millions of devices.
Hyperparameter tuning at scale is essential for building high-performance models in domains like computer vision and natural language processing. Large organizations, including Google and Microsoft, rely on distributed hyperparameter search to optimize complex models quickly. Frameworks like Optuna and Ray Tune make it easier to parallelize these searches across large clusters of GPUs or CPUs.
In reinforcement learning, companies like DeepMind and OpenAI have scaled RL algorithms to large distributed clusters for applications such as AlphaGo and OpenAI Five. Parallelizing the exploration of the environment by agents allows the model to learn more efficiently by leveraging massive computational power.
In Rust, federated learning can be implemented using the tch-rs crate and Rust’s native concurrency model. The following is a simplified implementation of federated learning, where multiple devices (represented as threads) train on local data and send their model updates to a central server:
use tch::{nn, nn::OptimizerConfig, Device, Tensor};
use std::sync::mpsc::{channel, Sender};
use std::thread;
// Simulate training on each device
fn train_on_device(device: Device, sender: Sender<Tensor>) {
let vs = nn::VarStore::new(device);
let model = nn::seq()
.add(nn::linear(vs.root(), 784, 512, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(vs.root(), 512, 10, Default::default()));
// Dummy input and target for simulation
let input = Tensor::randn(&[64, 784], (tch::Kind::Float, device));
let target = Tensor::randn(&[64, 10], (tch::Kind::Float, device));
// Forward and backward pass
let output = model.forward_t(&input, true);
let loss = output.mse_loss(&target, tch::Reduction::Mean);
loss.backward();
// Send the gradients back to the central server
let grads = vs.variables().grad();
sender.send(grads).unwrap();
}
fn main() {
let (tx, rx) = channel();
let devices = vec![Device::cuda(0), Device::cuda(1)];
// Spawn threads simulating federated learning devices
for device in devices {
let tx_clone = tx.clone();
thread::spawn(move || {
train_on_device(device, tx_clone);
});
}
// Aggregate gradients from all devices
let mut aggregated_grad = Tensor::zeros(&[512], (tch::Kind::Float, Device::Cpu));
for _ in 0..devices.len() {
let grad = rx.recv().unwrap();
aggregated_grad += &grad;
}
// Update the global model with aggregated gradients
aggregated_grad /= devices.len() as f64;
println!("Aggregated gradients: {:?}", aggregated_grad);
}
This implementation demonstrates the core idea of federated learning, where multiple devices train locally and send their gradients to a central server for aggregation. Rust’s concurrency model and message-passing make it well-suited for such distributed systems. Hyperparameter tuning at scale can be parallelized in Rust using crates like rayon or custom thread pools. Here’s an example of distributed hyperparameter search using Rust:
use rand::Rng;
use rayon::prelude::*;
use std::sync::Mutex;
fn evaluate_model(learning_rate: f64, batch_size: usize) -> f64 {
// Simulate model evaluation by returning a random accuracy score
let mut rng = rand::thread_rng();
rng.gen_range(0.0..1.0)
}
fn main() {
let learning_rates = vec![0.001, 0.01, 0.1];
let batch_sizes = vec![32, 64, 128];
let results = Mutex::new(vec![]);
learning_rates.par_iter().for_each(|&lr| {
batch_sizes.par_iter().for_each(|&bs| {
let accuracy = evaluate_model(lr, bs);
results.lock().unwrap().push((lr, bs, accuracy));
});
});
println!("Hyperparameter tuning results: {:?}", results);
}
In this example, hyperparameters like learning rate and batch size are evaluated in parallel, simulating the process of hyperparameter tuning at scale. The rayon crate allows for easy parallelization across available CPU cores.
Advanced scalable deep learning topics such as federated learning, distributed hyperparameter tuning, and reinforcement learning in distributed systems push the boundaries of what is possible with machine learning at scale. Rust’s performance and memory safety make it an excellent language for implementing such advanced systems. By leveraging Rust’s concurrency features and libraries like tch-rs, developers can build scalable, privacy-preserving, and high-performance distributed training systems that meet the demands of modern deep learning applications. From federated learning in decentralized environments to optimizing models using large-scale hyperparameter tuning, Rust provides the tools and infrastructure necessary for these cutting-edge techniques.
19.6. Conclusion
Chapter 19 equips you with the knowledge and skills to implement scalable deep learning and distributed training systems using Rust. By mastering these techniques, you can build models that efficiently handle the demands of large-scale data and complex computations, ensuring they remain performant and reliable as they scale.
19.6.1. Further Learning with GenAI
These prompts are designed to deepen your understanding of scalable deep learning and distributed training in Rust. Each prompt encourages exploration of advanced concepts, implementation techniques, and practical challenges in building scalable and efficient deep learning models.
Analyze the challenges of scaling deep learning models. How can Rust be used to address issues like communication overhead and load balancing in distributed training environments?
Discuss the differences between data parallelism and model parallelism. How can Rust be used to implement both strategies, and what are the key considerations in choosing the right approach for a given model?
Examine the role of communication strategies in distributed training. How can Rust be used to implement parameter servers or collective communication, and what are the trade-offs between different synchronization methods?
Explore the challenges of partitioning models for parallel training. How can Rust be used to efficiently split models across multiple GPUs or CPUs, and what are the best practices for ensuring minimal communication overhead?
Investigate the use of orchestration tools like Kubernetes for managing distributed training environments. How can Rust be integrated with these tools to deploy and monitor large-scale training jobs?
Discuss the importance of fault tolerance in distributed training. How can Rust be used to implement checkpointing and recomputation strategies to ensure training robustness and reliability?
Analyze the impact of batch size and gradient accumulation on training scalability. How can Rust be used to experiment with different batch sizes in distributed settings, and what are the implications for model convergence?
Examine the role of hardware accelerators like TPUs in scalable deep learning. How can Rust be integrated with specialized hardware to accelerate training, and what are the challenges in optimizing for different hardware architectures?
Explore the benefits and challenges of federated learning. How can Rust be used to implement federated learning systems that preserve data privacy while enabling distributed training?
Discuss the significance of hyperparameter tuning at scale. How can Rust be used to implement distributed hyperparameter optimization techniques, and what are the trade-offs between different tuning strategies?
Investigate the use of reinforcement learning in distributed environments. How can Rust be used to parallelize exploration and training in reinforcement learning algorithms, and what are the challenges in ensuring scalability?
Examine the role of monitoring and logging in distributed training. How can Rust be used to implement comprehensive monitoring systems that track model performance, resource usage, and potential bottlenecks?
Discuss the challenges of deploying distributed training systems in production. How can Rust be used to optimize deployment workflows, and what are the key considerations in ensuring reliability and scalability?
Analyze the impact of communication latency on distributed training efficiency. How can Rust be used to minimize latency and improve synchronization across distributed workers?
Explore the potential of hybrid parallelism in deep learning. How can Rust be used to combine data and model parallelism for training extremely large models, and what are the challenges in balancing the two approaches?
Discuss the significance of distributed file systems in scalable deep learning. How can Rust be used to integrate with distributed storage solutions, and what are the best practices for managing large datasets in distributed environments?
Investigate the use of distributed deep learning frameworks in Rust. How do these frameworks compare to established tools like TensorFlow and PyTorch, and what are the advantages of using Rust for distributed training?
Examine the role of distributed optimization algorithms in scalable deep learning. How can Rust be used to implement distributed optimization techniques, such as synchronous and asynchronous SGD, and what are the implications for model convergence?
Explore the challenges of real-time distributed training. How can Rust’s concurrency features be leveraged to handle real-time data streams in distributed training environments?
Discuss the future of scalable deep learning in Rust. How can the Rust ecosystem evolve to support cutting-edge research and applications in distributed training, and what are the key areas for future development?
Let these prompts inspire you to explore new frontiers in scalable deep learning and contribute to the growing field of AI and machine learning.
19.6.2. Hands On Practices
These exercises are designed to provide practical experience with scalable deep learning and distributed training in Rust. They challenge you to apply advanced techniques and develop a deep understanding of implementing and optimizing distributed training systems through hands-on coding, experimentation, and analysis.
Exercise 19.1: Implementing Data Parallelism for Distributed Training
Task: Implement a data-parallel training system in Rust using the
tch-rscrate. Train a deep learning model on a large dataset using multiple GPUs or CPUs and evaluate the impact on training speed and model accuracy.Challenge: Experiment with different synchronization strategies, such as synchronous and asynchronous training, and analyze their effects on convergence and scalability.
Exercise 19.2: Building a Model-Parallel Training System
Task: Implement a model-parallel training system in Rust, focusing on splitting a large model across multiple GPUs or CPUs. Train the model and evaluate the efficiency of model parallelism in handling large-scale computations.
Challenge: Experiment with different model partitioning strategies, such as pipeline parallelism, and analyze the trade-offs between communication overhead and training speed.
Exercise 19.3: Deploying a Distributed Training Job Using Kubernetes
Task: Set up a distributed training environment using Kubernetes and deploy a Rust-based deep learning model for distributed training. Monitor the training job, track resource usage, and optimize the deployment for scalability.
Challenge: Experiment with different Kubernetes configurations, such as pod autoscaling and distributed storage integration, to optimize training efficiency and resource utilization.
Exercise 19.4: Implementing Federated Learning in Rust
Task: Implement a federated learning system in Rust, focusing on distributing the training across multiple edge devices while preserving data privacy. Train a model on decentralized data and evaluate the performance of federated learning compared to centralized training.
Challenge: Experiment with different federated learning algorithms, such as FedAvg, and analyze the impact of communication frequency and data heterogeneity on model convergence.
Exercise 19.5: Scaling Hyperparameter Tuning with Distributed Optimization
Task: Implement a distributed hyperparameter optimization system in Rust using techniques like grid search, random search, or Bayesian optimization. Apply the system to tune the hyperparameters of a deep learning model in a distributed environment and evaluate the impact on model performance.
Challenge: Experiment with different optimization strategies and analyze the trade-offs between exploration and exploitation in hyperparameter tuning at scale.
By completing these challenges, you will gain hands-on experience and develop a deep understanding of the complexities involved in building and deploying scalable deep learning models, preparing you for advanced work in AI and distributed systems.
Comments