Chapter 4
Deep Learning Crates in Rust Ecosystem
"The tools we use to build intelligent systems must be as robust and efficient as the models themselves. Rust offers a promising foundation for the next generation of AI frameworks." — Andrew Ng
Chapter 4 of "Deep Learning via Rust" (DLVR) delves into the deep learning crates within the Rust ecosystem, examining how Rust's unique features—such as memory safety, an ownership model, and concurrency—support AI development. Beginning with an introduction to Rust's strengths and the setup of a deep learning environment, the chapter provides hands-on examples using crates like tch-rs. It offers an in-depth exploration of tch-rs, a Rust wrapper for PyTorch, demonstrating its ability to leverage PyTorch’s deep learning capabilities while upholding Rust's performance and safety standards. Key features such as tensor operations and automatic differentiation are discussed, along with practical examples of building and training neural networks. A comparative analysis of tch-rs with other Rust-based tools guides readers in selecting crates based on specific project needs, such as performance, flexibility, or compatibility. The chapter concludes by encouraging readers to contribute to the open-source Rust deep learning community, offering best practices and steps for enhancing these crates. Chapter 4 thus equips readers to effectively use Rust for deep learning while empowering them to support the growth of Rust’s AI ecosystem.
4.1. Introduction to Rust for Deep Learning
Rust, as a systems-level programming language, offers a unique blend of performance and safety, making it an excellent choice for deep learning (DL) and machine learning (ML) applications that demand high computational power and large-scale parallelism. Unlike higher-level languages like Python, Rust achieves performance levels comparable to C and C++ while offering memory safety guarantees through its ownership and borrowing models. This is critical in the context of deep learning, where efficient memory management is paramount due to the large datasets and models involved. Rust's ability to prevent common memory-related bugs, such as null pointer dereferencing and data races, significantly reduces the risk of runtime errors, which are often challenging to debug in large-scale systems. This memory safety is achieved without the need for a garbage collector, meaning that Rust applications can operate with minimal overhead, ensuring low-latency and high-throughput performance. Additionally, Rust's concurrency model, which leverages its ownership rules to prevent data races at compile time, enables developers to build highly parallelized applications that can efficiently utilize multi-core processors or distributed computing environments. In deep learning tasks that involve parallel data processing, multi-threaded training routines, or GPU acceleration, Rust's safety guarantees and control over system resources ensure that models are both performant and reliable, making it an ideal language for production-level AI applications.
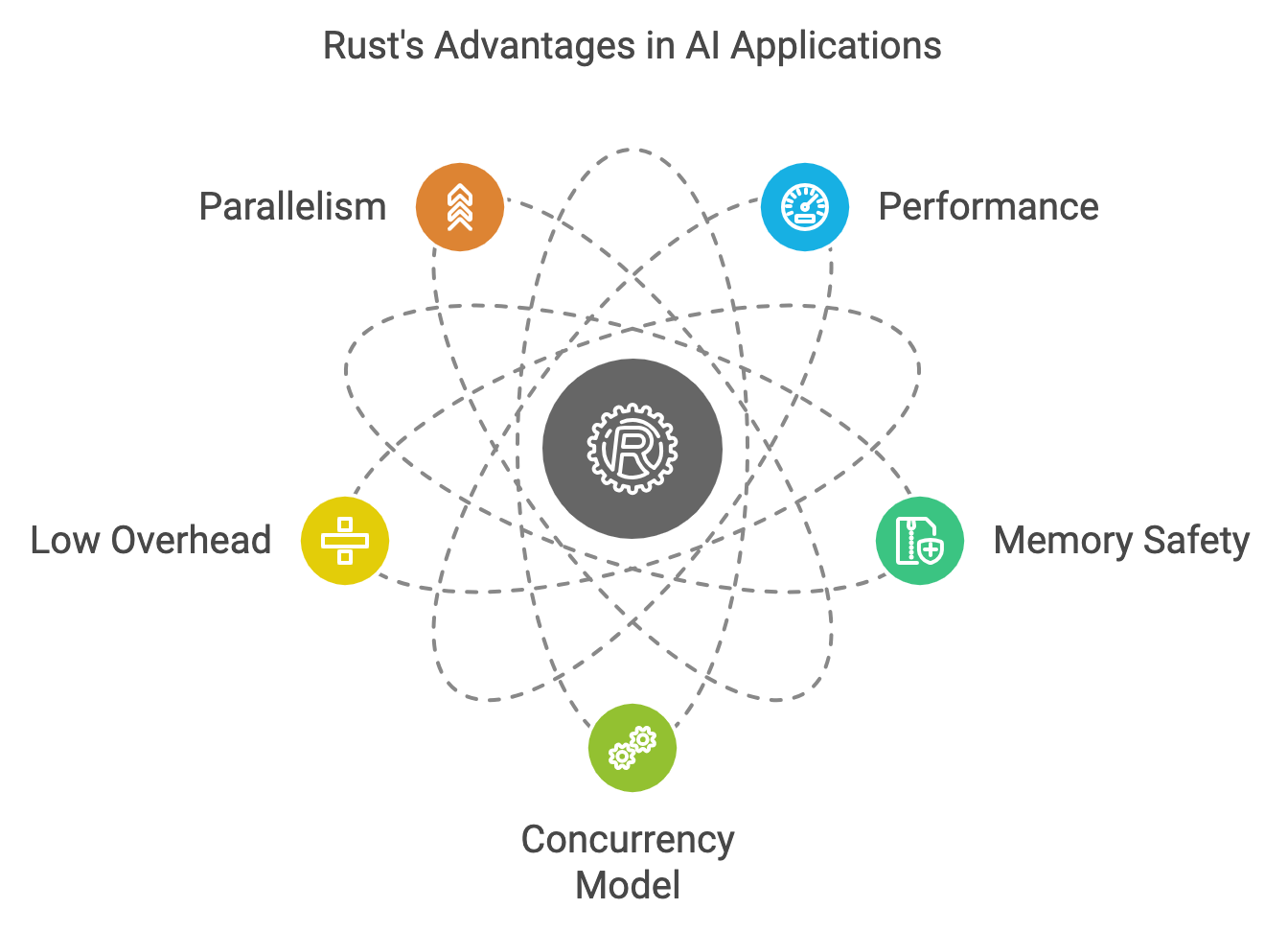
Figure 1: Key advantages of Rust for Deep Learning model development and inference.
Mathematically, deep learning involves the optimization of large, multidimensional parameter spaces. Each layer in a neural network can be represented as a set of weight matrices $W$ and bias vectors $b$, where forward propagation computes the activations $\mathbf{a}^{(l)}$ for each layer $l$ based on the input data $\mathbf{x}$ and weight parameters. The typical operation of forward propagation for a layer in a neural network is:
$$ \mathbf{z}^{(l)} = W^{(l)} \mathbf{a}^{(l-1)} + b^{(l)} $$
$$ \mathbf{a}^{(l)} = f(\mathbf{z}^{(l)}) $$
where $f$ is a non-linear activation function such as ReLU, sigmoid, or tanh. The objective in deep learning is to minimize the loss function $L(\hat{y}, y)$, where $\hat{y}$ is the predicted output and $y$ is the true label. Gradient-based optimization methods, such as stochastic gradient descent (SGD) or Adam, are used to compute the gradients of the loss function with respect to the weights and adjust them iteratively to reduce the loss.
Rust’s performance and memory management are particularly advantageous during the backpropagation process, where the gradients $\nabla_W L$ need to be computed for each layer to update the model parameters. In complex networks with millions of parameters, memory overhead becomes a bottleneck, and Rust’s ownership model ensures that resources are managed effectively, preventing memory leaks or inefficient garbage collection cycles. This results in faster and more reliable deep learning training cycles.
One of the key reasons for Rust’s growing adoption in AI is its ability to handle concurrency without sacrificing safety. In deep learning, concurrency is essential for tasks such as parallelizing matrix computations or distributing model training across multiple GPUs or nodes in a cluster. Rust’s lightweight threading model allows developers to safely execute parallel computations while avoiding the pitfalls of concurrent programming in languages that don’t provide the same level of safety guarantees. Rust’s threading mechanisms and Send and Sync traits enforce data sharing rules that prevent race conditions, making it easier to scale deep learning applications across multiple cores or distributed environments.
The deep learning ecosystem in Rust is evolving rapidly, with crate like tch-rs playing significant roles in enabling deep learning workflows. tch-rs, a Rust binding for PyTorch, allows Rust developers to leverage the capabilities of PyTorch, one of the most popular deep learning frameworks. This provides an ideal blend of Rust’s performance and memory safety with PyTorch’s proven capabilities in neural network training, automatic differentiation, and GPU acceleration. From a practical perspective, setting up Rust for deep learning is straightforward. The Rust package manager, Cargo, simplifies dependency management, allowing developers to easily install and configure deep learning libraries. For example, to use tch-rs, you would first install Rust by following the instructions at [rust-lang.org](https://www.rust-lang.org/). Once Rust is installed, you can create a new project and add the tch crate:
cargo new deep_learning_project
cd deep_learning_project
cargo add tch
This command creates a new Rust project and installs the tch crate, which provides the bindings to PyTorch. You can now build and train deep learning models in Rust while leveraging PyTorch’s backend. Below is an example of implementing a simple neural network model using tch-rs:
[dependencies]
tch = "0.12.0"
use tch::{nn, nn::Module, nn::OptimizerConfig, Device, Tensor};
fn main() {
// Define the device (use GPU if available, otherwise CPU)
let device = Device::cuda_if_available();
// Initialize the network
let vs = nn::VarStore::new(device);
let net = nn::seq()
.add(nn::linear(&vs.root().sub("layer1"), 3, 128, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(&vs.root().sub("layer2"), 128, 64, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(&vs.root().sub("layer3"), 64, 1, Default::default()));
// Set up the Adam optimizer
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
// Create dummy input and target data
let xs = Tensor::randn(&[100, 3], (tch::Kind::Float, device));
let ys = Tensor::randn(&[100, 1], (tch::Kind::Float, device));
// Training loop
for epoch in 1..200 {
let predictions = net.forward(&xs);
let loss = predictions.mse_loss(&ys, tch::Reduction::Mean);
opt.backward_step(&loss);
println!("Epoch: {}, Loss: {}", epoch, f64::from(loss));
}
}
In this example, a simple feedforward neural network is constructed using tch-rs. The network contains three fully connected layers, with ReLU activations between the layers. The Adam optimizer is used to update the weights, and the model is trained using mean squared error (MSE) as the loss function. The training process involves multiple epochs where the network's predictions are compared to the true labels, and the optimizer adjusts the weights based on the gradients computed through backpropagation.
This demonstrates how easily Rust integrates with deep learning libraries and how efficiently it can handle the memory and compute requirements for large models. Using tch-rs, developers can build complex models, train them on large datasets, and deploy them in production environments where performance and memory safety are critical.
In more complex settings, Rust’s concurrency model and safety features play an even more significant role. In distributed deep learning, where model parameters are spread across multiple nodes and GPUs, Rust’s safety guarantees ensure that data is shared and accessed correctly without race conditions. Parallelizing matrix computations across multiple threads or devices is common in deep learning workloads, and Rust’s ability to enforce memory and data ownership rules at compile time makes it an ideal choice for these large-scale tasks.
Furthermore, Rust’s performance in real-time or near-real-time systems makes it suitable for deploying models in production environments where latency is critical. Applications such as autonomous vehicles, robotics, or real-time anomaly detection benefit from Rust’s low-level control over system resources, enabling models to be executed efficiently on both high-performance servers and resource-constrained embedded devices.
In the AI industry, Rust is increasingly being adopted for tasks requiring both high performance and reliability. Deep learning frameworks like tch-rs provides the tools necessary to build and train neural networks while leveraging Rust’s performance characteristics. In production environments, Rust’s memory safety, concurrency support, and performance make it a compelling choice for deploying models that must handle large volumes of data with low latency and high reliability.
In conclusion, Rust’s systems-level capabilities, memory safety, and growing ecosystem of deep learning libraries make it a strong contender for building AI applications. The combination of high performance, safe concurrency, and deterministic memory management is particularly suited for large-scale and production-level deep learning workloads. Rust’s ability to integrate with established deep learning libraries like PyTorch through tch-rs, while also offering native deep learning frameworks like burn, positions it as a promising language for the future of AI development.
4.2. Overview of the tch-rs Crate
The tch-rs crate serves as a Rust wrapper for the widely-used PyTorch library, allowing developers to harness the deep learning capabilities of PyTorch while taking advantage of Rust’s performance, safety, and concurrency features. By providing a seamless interface between Rust and PyTorch, tch-rs enables developers to build and train deep learning models in Rust without sacrificing the rich functionality and ecosystem that PyTorch offers.
Figure 2: Rust tch-rs crate, wrapper for PyTorch C++ API (libtorch).
Mathematically, deep learning relies on tensor operations as the foundation of neural network computations. Tensors are multi-dimensional arrays that generalize matrices to higher dimensions, and they are used to store data, weights, activations, and gradients. In deep learning models, the forward propagation involves matrix multiplications, element-wise operations, and other tensor manipulations, all of which are efficiently handled by the tch-rs crate through PyTorch’s backend. For example, given a weight matrix $W$, bias vector $b$, and input $x$, the output $z$ for a fully connected neural network layer can be computed as:
$$z = W \cdot x + b$$
In tch-rs, this operation is performed using its tensor API, which mirrors PyTorch’s native API but provides Rust’s memory safety guarantees and type system.
One of the core features of the tch-rs crate is its support for automatic differentiation, which is essential for training deep learning models. Automatic differentiation allows for the computation of gradients with respect to model parameters during backpropagation. This is critical for optimization algorithms such as stochastic gradient descent (SGD) or Adam, which adjust the model's parameters to minimize the loss function. When performing backpropagation, the chain rule is applied to compute gradients across multiple layers. For instance, given a loss function $L$ and parameters $W$, the gradient $\frac{\partial L}{\partial W}$ is computed automatically using autograd:
$$ \frac{\partial L}{\partial W} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial W} $$
Thetch-rs automates this process using PyTorch’s autograd engine, which tracks operations on tensors and computes gradients efficiently. This feature enables developers to focus on model architecture and training logic without manually implementing gradient computations, which can be error-prone and computationally intensive.
This advanced Rust program demonstrates training a fully connected feedforward neural network using the tch crate for deep learning. The task involves predicting continuous target values (regression) from input features, leveraging a randomly generated dataset for simplicity. The neural network consists of multiple layers, and the program employs the Adam optimizer to minimize the mean squared error (MSE) loss, refining the model's predictions over a series of epochs.
[dependencies]
tch = "0.12.0"
use tch::{nn, nn::ModuleT, nn::OptimizerConfig, Device, Tensor};
fn main() {
// Define the device (use GPU if available, otherwise CPU)
let device = Device::cuda_if_available();
// Initialize the network
let vs = nn::VarStore::new(device);
let net = nn::seq()
.add(nn::linear(&vs.root().sub("layer1"), 3, 128, Default::default()))
.add_fn(|xs| xs.relu())
.add_fn(|xs| xs.dropout(0.3, true)) // Use `add_fn` for dropout
.add(nn::linear(&vs.root().sub("layer2"), 128, 64, Default::default()))
.add_fn(|xs| xs.relu())
.add_fn(|xs| xs.dropout(0.3, true)) // Use `add_fn` for dropout
.add(nn::linear(&vs.root().sub("layer3"), 64, 1, Default::default()));
// Set up the Adam optimizer with weight decay
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
// Create synthetic dataset
let xs = Tensor::randn(&[1000, 3], (tch::Kind::Float, device));
let ys = Tensor::randn(&[1000, 1], (tch::Kind::Float, device));
// Batch size and number of epochs
let batch_size = 64;
let epochs = 50;
// Learning rate scheduler parameters
let lr_decay = 0.9;
let lr_decay_steps = 10;
let mut learning_rate = 1e-3; // Manually track learning rate
// Training loop
for epoch in 1..=epochs {
let mut total_loss = 0.0;
let n_batches = xs.size()[0] / batch_size;
for batch_idx in 0..n_batches {
let batch_start = batch_idx * batch_size;
let _batch_end = (batch_idx + 1) * batch_size;
// Create batches
let x_batch = xs.narrow(0, batch_start, batch_size);
let y_batch = ys.narrow(0, batch_start, batch_size);
// Forward pass
let predictions = net.forward_t(&x_batch, true); // Use forward_t for training
let loss = predictions.mse_loss(&y_batch, tch::Reduction::Mean);
// Backward pass and optimization step
opt.backward_step(&loss);
// Extract scalar loss value
total_loss += loss.double_value(&[]);
}
// Learning rate decay
if epoch % lr_decay_steps == 0 {
learning_rate *= lr_decay; // Adjust learning rate
opt.set_lr(learning_rate); // Update optimizer with new learning rate
}
println!(
"Epoch: {}, Avg Loss: {:.6}, Learning Rate: {:.6}",
epoch,
total_loss / n_batches as f64,
learning_rate
);
}
println!("Training complete.");
}
The code defines a three-layer neural network, where each layer applies a linear transformation followed by a ReLU activation, except for the final layer, which outputs a single value for regression. The network is initialized with random weights, and the Adam optimizer is configured to update these weights based on gradient descent. A synthetic dataset with 100 samples and 3 features serves as input, while the corresponding targets are also generated randomly. During training, the network computes predictions from the input data, calculates the MSE loss against the target values, and performs backpropagation to adjust the model's parameters iteratively. This process repeats over 200 epochs, with the loss decreasing as the model learns to approximate the target values better.
This simple example demonstrates how easily deep learning models can be built and trained using tch-rs. The tensor operations, automatic differentiation, and optimizer are all handled efficiently by the crate, leveraging PyTorch’s backend to perform fast matrix computations and gradient calculations. The tch-rs crate ensures that the Rust code maintains the same performance benefits of PyTorch while incorporating Rust’s safety and concurrency advantages.
Another notable feature of tch-rs is its ability to create custom layers and integrate them into neural network architectures. In cases where a specialized layer or operation is needed, developers can define their own layers by subclassing existing modules and implementing custom forward passes. This allows for a great degree of flexibility in model design, making it possible to experiment with novel architectures and layer configurations.
In addition, tch-rs integrates well with Rust’s concurrency features, enabling multi-threaded training or inference. While PyTorch itself supports parallelism on GPUs, Rust’s native concurrency tools, such as threads and async tasks, can be leveraged to manage data loading, model inference, or even distributed training in a safe and efficient manner. This makes Rust, combined with tch-rs, a powerful tool for building scalable AI applications that need to handle large amounts of data and computations across distributed systems.
The tch-rs crate, a Rust wrapper for PyTorch's C++ API, has evolved significantly across its versions to enhance usability, stability, and performance for deep learning tasks in Rust. Earlier versions focused on providing bindings to core PyTorch functionalities, enabling Rust developers to leverage the mature PyTorch ecosystem. Over time, the crate introduced improved support for GPU acceleration, better handling of tensor operations, and extended APIs for defining and training complex models like transformers. Recent versions have prioritized seamless integration with PyTorch features such as TorchScript, advanced automatic differentiation, and state-of-the-art optimizers. Version 0.12, the most stable and recommended release, is noted for its enhanced reliability, comprehensive API coverage, and refined error handling, making it suitable for both research and production. With consistent updates aligned with PyTorch releases, tch-rs version 0.12 strikes an optimal balance between cutting-edge features and robust, stable performance.
From an industry perspective, the integration of Rust with PyTorch through tch-rs opens up new possibilities for deploying deep learning models in production environments. Rust’s memory safety, lack of a garbage collector, and deterministic behavior are critical in systems where performance and reliability are paramount, such as autonomous vehicles, robotics, or real-time data processing systems. By using tch-rs, developers can write AI applications that take full advantage of PyTorch’s deep learning capabilities while ensuring that their code is robust, safe, and scalable.
In conclusion, the tch-rs crate provides an efficient and powerful interface between Rust and PyTorch, enabling developers to build deep learning models in a language that emphasizes performance and safety. With support for tensor operations, neural network layers, automatic differentiation, and custom layer creation, tch-rs allows developers to implement both standard and custom deep learning models. The growing adoption of tch-rs in industry and academia reflects its potential to transform how deep learning models are built and deployed in production systems, where speed, concurrency, and memory management are critical concerns.
4.3. Exploring the burn Crate
The burn crate is a modular and flexible deep learning framework in Rust that aims to provide a native, end-to-end deep learning experience, distinct from the PyTorch-based tch-rs. While tch-rs serves as a Rust binding to the established PyTorch library, burn is designed from the ground up in Rust, focusing on extensibility, flexibility, and leveraging Rust's powerful type system and memory management model. This allows developers to build custom deep learning models in a highly modular way, making it ideal for research, experimentation, and applications requiring fine-grained control over every aspect of model construction and training.

Figure 3: Burn.dev Framework for deep learning.
At the mathematical level, deep learning revolves around tensor operations, model architectures, optimization algorithms, and training procedures. A typical neural network layer can be described mathematically as:
$$ z^{(l)} = W^{(l)} a^{(l-1)} + b^{(l)} $$
$$ a^{(l)} = f(z^{(l)}) $$
where $z^{(l)}$ is the pre-activation output of the $l$-th layer, $W^{(l)}$ represents the weight matrix, $b^{(l)}$ is the bias vector, $a^{(l)}$ is the activation, and $f$ is the non-linear activation function (e.g., ReLU, Sigmoid). Optimizing the network’s parameters involves computing the gradients $\nabla_W L$ using backpropagation and updating the weights iteratively through optimizers like SGD or Adam. The burn crate provides a modular way to define these layers, optimizers, and the training loop, allowing users to customize and experiment with different architectures.
The key components of burn include its tensor operations, neural network modules, optimizers, and training loop abstractions. Tensors, the foundational data structure in deep learning, are multi-dimensional arrays that store inputs, weights, activations, and gradients. In burn, tensors are built on top of the burn-tensor submodule, which is designed to be fast and flexible, leveraging Rust’s performance and safety guarantees. The tensor operations in burn are designed to be efficient and are implemented with an emphasis on memory safety, ensuring that operations such as matrix multiplications, element-wise operations, and reductions are executed safely and in parallel when needed.
One of the most important aspects of the burn crate is its modularity. Every neural network component, from individual layers to optimizers and loss functions, is treated as a module that can be easily swapped or extended. This modularity allows for a high degree of customization, enabling developers to build their own layers, activation functions, or even custom optimizers. For instance, you could create a new neural network layer by implementing the Module trait, which defines the forward pass of the layer, and plug it into the existing framework without having to rewrite the training loop or tensor operations.
A critical aspect of burn is its design philosophy, which contrasts with tch-rs. While tch-rs provides a Rust binding to the well-established PyTorch framework, allowing users to tap into PyTorch's vast ecosystem and optimized backend, burn is designed with a more flexible and native approach. This allows for deeper integration with Rust’s type system and ownership model, making it particularly well-suited for applications that require complete control over memory, performance, and concurrency. For example, burn leverages Rust’s strict type checking and ownership model to enforce safe borrowing rules and prevent memory errors, which are common in C++-based deep learning frameworks.
The flexibility and extensibility of burn are particularly valuable in research and experimentation. Researchers often need to modify existing models or create new architectures, and burn provides the infrastructure to do this efficiently. Whether experimenting with novel layers or custom loss functions, burn’s modular design ensures that these components can be integrated into a model with minimal changes to the rest of the code. This is a significant advantage for researchers who need to iterate quickly while ensuring that their code remains robust and efficient.
The following is a practical example of building and training a custom neural network using burn. This example demonstrates how to set up a simple feedforward network, define a loss function, and implement a training loop.
use burn::tensor::Tensor;
use burn::nn::{Linear, ReLU, Module};
use burn::optim::{Adam, Optimizer};
use burn::train::{TrainConfig, TrainingLoop};
fn main() {
// Define a simple feedforward network
#[derive(Module)]
struct SimpleNet {
layer1: Linear,
relu: ReLU,
layer2: Linear,
}
impl SimpleNet {
fn new() -> Self {
Self {
layer1: Linear::new(3, 128),
relu: ReLU::new(),
layer2: Linear::new(128, 1),
}
}
fn forward(&self, input: &Tensor) -> Tensor {
let out = self.layer1.forward(input);
let out = self.relu.forward(&out);
self.layer2.forward(&out)
}
}
// Initialize the network and optimizer
let net = SimpleNet::new();
let mut optimizer = Adam::new(net.parameters(), 1e-3);
// Create dummy data for training
let xs = Tensor::randn(&[100, 3]);
let ys = Tensor::randn(&[100, 1]);
// Define the training loop
let mut train_loop = TrainingLoop::new(TrainConfig::default(), net, optimizer);
// Train the network
for epoch in 0..100 {
let predictions = train_loop.model.forward(&xs);
let loss = predictions.mse_loss(&ys);
train_loop.step(loss);
println!("Epoch: {}, Loss: {:?}", epoch, loss);
}
}
In this example, we define a simple feedforward neural network using burn’s Linear and ReLU modules. The network consists of two fully connected layers with ReLU activation between them. The optimizer used is Adam, which is initialized with the model’s parameters, and we define a training loop using burn’s TrainingLoop abstraction. The model is trained on randomly generated dummy data, and during each epoch, the loss is computed using mean squared error (MSE), and the model parameters are updated.
This simple example illustrates the flexibility of burn in defining custom neural networks. The modularity of the crate allows developers to build neural networks from scratch, modify individual layers, and experiment with different architectures without being constrained by a monolithic framework. In this way, burn provides a balance between low-level control and high-level abstractions, making it suitable for both research and production-level AI applications.
An interesting extension of burn is its ability to support more complex architectures, such as Generative Adversarial Networks (GANs) or Transformers. GANs, for example, consist of two networks—a generator and a discriminator—that are trained simultaneously in a competitive manner. Implementing a GAN in burn would involve defining both networks as separate modules and setting up a custom training loop to alternate between updating the generator and the discriminator. Similarly, a Transformer model, which is heavily used in natural language processing, can be implemented by defining custom attention layers and feeding them into a multi-layered architecture.
Additionally, burn integrates well with other Rust crates, making it easy to extend its functionality. For example, burn can be combined with crates like ndarray for advanced tensor operations, rayon for parallel computing, or serde for serializing models to disk. This interoperability makes burn a powerful framework for developers who need to build custom deep learning pipelines that integrate tightly with other system components.
In the AI industry, modularity and extensibility are increasingly important, particularly in research and development. With deep learning models becoming more complex, frameworks that provide flexibility, like burn, enable rapid experimentation and development of novel architectures. Moreover, in production environments, Rust’s memory safety, lack of a garbage collector, and strong concurrency model ensure that models built using burn are both performant and reliable, capable of scaling across different hardware configurations without the overhead common in higher-level languages like Python.
In conclusion, the burn crate provides a highly modular and flexible framework for deep learning in Rust. Its ability to define custom models, layers, and optimizers, combined with Rust’s type system and performance guarantees, makes it ideal for research and production environments. By allowing developers to build everything from simple feedforward networks to complex architectures like GANs and Transformers, burn is positioned to become a key player in the growing Rust deep learning ecosystem. However, in the DLVR book, we will primarily focus on the tch-rs crate due to its maturity and established stability within the Rust ecosystem. Tch-rs, as a Rust wrapper for PyTorch, has reached a level of reliability and feature completeness that aligns well with both introductory and advanced deep learning applications. This maturity allows us to concentrate on developing robust, performant models without concerns over frequent changes or limitations, ensuring a smooth learning experience for readers. While burn holds great potential, tch-rs offers the stability needed to comprehensively explore Rust-based deep learning concepts in DLVR.
4.4. Comparative Analysis of tch-rs and burn
The tch-rs and burn crates both provide powerful tools for building deep learning models in Rust, yet their fundamental differences in design, functionality, and integration with the Rust ecosystem present developers with distinct advantages and trade-offs. To better understand which crate is more appropriate for a given project, a comprehensive comparison must delve into their architectural principles, performance characteristics, scalability, and the flexibility each provides in deep learning research and production environments.
Both tch-rs and burn offer robust tensor operations as the foundation for building deep learning models. In deep learning, tensors are multi-dimensional arrays that store data, model weights, and intermediate outputs. Core operations, such as matrix multiplication, element-wise transformations, and reductions, form the backbone of model training and inference. Mathematically, these operations can be expressed as:
$$ \mathbf{z} = \mathbf{W} \cdot \mathbf{a} + \mathbf{b} $$
$$ \mathbf{a}^{(l)} = f(\mathbf{z}^{(l)}) $$
Here, $\mathbf{W}$ and $\mathbf{b}$ are the weight matrix and bias vector for layer $l$, and $f$ represents the non-linear activation function (e.g., ReLU, tanh, sigmoid). The goal of training is to adjust the parameters $\mathbf{W}$ and $\mathbf{b}$ by minimizing the loss function $L(\hat{y}, y)$ using optimization methods such as stochastic gradient descent (SGD) or the Adam optimizer. Backpropagation calculates gradients with respect to model parameters using the chain rule:
$$ \nabla_W L = \frac{\partial L}{\partial W} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial W} $$
In tch-rs, tensor operations and gradient computations are handled by PyTorch’s backend, one of the most optimized deep learning frameworks globally. PyTorch’s design includes highly efficient implementations of linear algebra routines, automatic differentiation, and GPU acceleration via CUDA. Since tch-rs is a Rust wrapper for PyTorch, it inherits these performance benefits without requiring Rust-native implementations. For example, when performing matrix multiplications or convolutions, tch-rs directly delegates these operations to PyTorch’s highly-tuned libraries. As a result, models built using tch-rs can match or even exceed the performance of models written in Python, especially when training large-scale models on GPUs.
In contrast, burn is written entirely in Rust and does not rely on an external backend like PyTorch, which allows for deeper integration with Rust’s type system, ownership model, and memory safety guarantees. However, this independence from established deep learning frameworks also means that burn lacks the same level of optimization, particularly for GPU operations. While burn is continually evolving, it does not currently match the raw speed of tch-rs for handling large-scale data or GPU-intensive tasks. Despite this, burn excels in providing flexibility, modularity, and safety, which can be crucial in certain applications where Rust’s memory safety and concurrency features are essential.
One of burn's core advantages is its modular architecture, which allows developers to build and experiment with custom neural network architectures, layers, optimizers, and training loops. In burn, every component—from tensors and layers to optimizers and loss functions—is treated as a modular unit, making it easy to extend or modify. For example, custom layers can be built by implementing the Module trait, and developers can define novel activation functions or optimization algorithms that seamlessly integrate with the existing framework. This modular design is particularly useful in research environments, where novel model architectures or non-standard layers may need to be implemented for experimentation. Conversely, while tch-rs provides access to PyTorch’s vast array of pre-built components, it is more challenging to extend these components within Rust due to the constraints of being a wrapper around a foreign library.
The flexibility of burn extends beyond just model architecture. As a Rust-native framework, it integrates well with other Rust crates and tools. For instance, burn can be combined with rayon for parallel computing, ndarray for advanced mathematical operations, or serde for serializing and deserializing models. This makes burn an ideal choice for projects requiring close integration with systems-level Rust code, such as real-time applications, embedded systems, or distributed systems where performance and memory control are paramount. In such environments, the ability to control memory allocation, borrowing, and freeing—features central to Rust's design—becomes crucial, especially when managing large datasets or training models in a multi-threaded or distributed setup.
For GPU performance, tch-rs holds a significant advantage due to its reliance on PyTorch’s CUDA backend, highly optimized for NVIDIA GPUs. Tch-rs inherits these CUDA capabilities, allowing Rust developers to train models at near-optimal speeds for deep learning tasks demanding computational power, such as image classification using convolutional neural networks (CNNs) or sequence processing with transformers.
In terms of scaling models across multiple GPUs or distributed systems, PyTorch’s Distributed Data Parallel (DDP) capabilities allow tch-rs to efficiently parallelize computations across devices. This makes tch-rs compelling for large-scale projects, such as training models for natural language processing (NLP) on extensive datasets or managing real-time recommendations in production environments. In contrast, burn offers powerful multi-threading capabilities through Rust’s concurrency model but lacks the mature GPU support that PyTorch provides. Although burn’s multi-threading features are effective for CPU-based parallelism, it is not optimized for GPU acceleration to the same extent as PyTorch.
To illustrate these performance differences, consider training the same neural network using both tch-rs and burn. The raw performance, especially on a GPU, would likely favor tch-rs due to PyTorch’s CUDA support. However, in scenarios where memory management, safety, and multi-threading are more critical than raw speed, burn’s native Rust implementation would excel, offering a safer, more flexible environment.
Ultimately, the choice between tch-rs and burn depends on specific project needs. For performance, particularly in GPU-accelerated environments, tch-rs is the clear winner due to its reliance on PyTorch’s highly optimized backend. However, for projects prioritizing flexibility, modularity, and integration with Rust’s ecosystem, burn offers distinct advantages. Burn is more suitable for research and experimentation, where custom layers, architectures, or novel optimizers are needed, and it excels in applications requiring robust memory safety and concurrency.
In conclusion, both tch-rs and burn are valuable in Rust’s growing deep learning ecosystem, addressing different aspects of deep learning development. Understanding their strengths and limitations enables developers to choose the right framework for their requirements, balancing performance, safety, and flexibility. In the DLVR book, we will focus on tch-rs due to its maturity and established stability, which provides a reliable foundation for readers to explore Rust-based deep learning effectively. Burn, while promising, currently lacks the level of maturity and optimization required for large-scale, GPU-intensive projects, making tch-rs the preferred choice for in-depth learning and practical applications in DLVR.
4.5. Extending and Contributing to Rust Deep Learning Crates
The open-source nature of Rust's deep learning crates, such as tch-rs or burn, allows for continuous development and enhancement by the community. Open-source contributions play a vital role in advancing deep learning frameworks, enabling developers to improve performance, add new features, and fix bugs collaboratively. As Rust's ecosystem continues to grow, the collective efforts of contributors can help push the boundaries of deep learning, creating frameworks that are both powerful and efficient. Understanding how to extend these crates and contribute effectively is essential for those looking to actively participate in the development of Rust-based deep learning tools.
Mathematically, the potential for extending these frameworks lies in the addition of new models, layers, optimizers, and custom operations that enhance functionality. For instance, creating novel neural network layers—such as attention mechanisms or custom recurrent units—can extend the applicability of these frameworks to more complex tasks. Consider the implementation of a new optimizer, say a variant of the Adam optimizer, which adjusts the learning rates dynamically based on momentum and gradients. The core idea of the Adam algorithm is to compute running averages of both the gradient and its square:
$$ m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t $$
$$ v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 $$
where $g_t$ is the gradient at time step $t$, and $m_t$ and $v_t$ are estimates of the first and second moments, respectively. Extending a framework like burn to include a variant of Adam could involve modifying the moment update equations, or introducing new hyperparameters for controlling the learning rate adjustment. Understanding these mathematical foundations is crucial when contributing new features to deep learning crates.
From a conceptual standpoint, contributing to open-source projects like tch-rs or burn requires a deep understanding of the framework’s architecture, codebase, and existing capabilities. Identifying areas for improvement involves looking for gaps in the current feature set, performance bottlenecks, or potential integrations with other libraries or systems. For example, burn might benefit from new layers or activation functions, such as LeakyReLU or SELU, that could be added by contributors. Similarly, tch-rs could be extended by integrating additional PyTorch features, such as new data augmentation techniques or more advanced neural network layers.
The process of contributing to these open-source projects typically follows a well-defined set of best practices. Contributors should begin by exploring the project's issue tracker or roadmap to identify areas where help is needed. Code contributions should adhere to the project’s style and standards, ensuring consistency and maintainability. Rust’s community places a strong emphasis on code quality, making documentation, testing, and benchmarking essential components of any contribution. Testing is especially important in deep learning, where models and operations can behave unpredictably without proper verification. Writing unit tests for new layers, optimizers, or loss functions ensures that they behave as expected under different scenarios.
Another important aspect of contributing is the collaborative environment facilitated by tools like Git, GitHub, and GitLab. Contributors should follow a clear workflow, beginning by forking the repository and creating a new branch for their feature or bug fix. Changes should be kept modular, focusing on one improvement at a time, and accompanied by detailed commit messages that explain the rationale behind each change. Engaging with other developers through code reviews and discussions helps ensure that contributions align with the project’s goals and adhere to best practices.
Open-source contributions to deep learning frameworks in Rust are not limited to code improvements. Writing or enhancing documentation is an equally valuable way to contribute, as it helps new users understand how to use the framework and extends the reach of the project. Comprehensive documentation should cover not only API references but also tutorials and use cases that demonstrate the capabilities of the crate in real-world scenarios.
In the context of deep learning, benchmarking is also crucial. With performance being a key factor in model training and inference, any new feature or optimization should be benchmarked against existing implementations to ensure that it either improves performance or maintains it without adding overhead. Rust’s ecosystem includes powerful tools for benchmarking, such as the criterion crate, which can be used to measure the performance of tensor operations, training loops, or custom optimizers. Benchmarking results should be included as part of the contribution to provide evidence of the feature's efficiency.
Finally, community involvement is key to the long-term success of open-source projects. Maintaining an active role in the Rust deep learning community involves not only contributing code but also engaging in discussions, offering feedback on others’ contributions, and helping triage issues. Collaboration with other developers through discussions on GitHub issues or community forums like Reddit or Discord can lead to innovative solutions and improvements that benefit the entire ecosystem. By participating in the community, developers help shape the future of Rust-based deep learning frameworks and ensure that they evolve to meet the growing demands of both research and industry.
In conclusion, extending and contributing to Rust’s deep learning crates, such as tch-rs and burn, requires a balance of technical understanding, practical coding skills, and collaborative engagement with the open-source community. Contributors can improve these frameworks by adding new features, optimizing performance, and enhancing documentation, all while adhering to Rust’s high standards for code quality. By actively participating in the community, developers can help push the boundaries of what’s possible with Rust in the deep learning domain, ultimately advancing the state of AI in both research and production settings.
4.7. Hugging Face Candle Crate
The Hugging Face Candle crate represents a transformative step in the deep learning landscape for Rust, offering a highly optimized, Rust-native library designed to train and deploy large-scale machine learning models. Developed by Hugging Face, a leader in the field of natural language processing and machine learning, Candle is crafted with a focus on lightweight performance, extensibility, and modern deep learning requirements, particularly for transformer-based architectures like large language models (LLMs). By leveraging Rust's core strengths, such as memory safety and concurrency, Candle minimizes runtime overhead while ensuring stability, making it an ideal choice for developers building cutting-edge AI applications in Rust.
Figure 4: Architecture, features, models and future development of Candle crate.
Candle's architecture revolves around a tensor-centric design, where tensors act as the fundamental data structure for storing and manipulating numerical data. Built with modularity in mind, the crate integrates a computation graph that efficiently handles forward passes and backpropagation for training deep neural networks. This architecture supports the rigorous demands of transformer-based models like GPT, BERT, and Vision Transformers, enabling the seamless integration of multi-head attention, layer normalization, and other essential components of modern neural networks. Candle is optimized for scalability, featuring support for distributed computing, mixed-precision training, and offloading computations to hardware accelerators such as GPUs. Its modular design encourages the addition of custom layers, kernels, and optimizers, making it a versatile tool for both research and production environments.
Figure 5: Key capabilities and advantages of Candle crate.
A key strength of Candle lies in its comprehensive support for both training and inference workflows. For training, Candle provides features like automatic differentiation, gradient accumulation, and dynamic learning rate scheduling. These are crucial for fine-tuning pre-trained models or training custom architectures from scratch. On the inference side, Candle excels with its efficient execution pipeline, ensuring low-latency predictions even on constrained devices. This dual capability allows developers to experiment with model development during training while ensuring efficient deployment in production, addressing the full lifecycle of deep learning systems.
Candle also includes a growing library of pre-built models tailored for modern applications. Notable examples are GPT-style language models, BERT-based encoders, and Vision Transformers, complete with pre-trained weights and configurations. These models serve as robust baselines for various tasks, such as natural language understanding, text generation, and image recognition. The availability of pre-trained models reduces the barrier to entry for developers and researchers looking to quickly apply state-of-the-art techniques in their domains. Moreover, Candle's documentation and examples provide a solid foundation for adapting these models to specific datasets and use cases.
The candle-core crate, the foundation of the framework, focuses on efficient tensor operations, automatic differentiation, and robust device management, making it ideal for both foundational and advanced computations. On top of this, candle-nn introduces higher-level abstractions such as layers, activation functions, and optimizers, enabling seamless construction of complex neural networks. For transformer-based models, the candle-transformers crate offers implementations of popular architectures like GPT and BERT, with pre-trained weights and utilities for natural language processing tasks. The candle-examples crate provides practical demonstrations of how to use the framework, covering a variety of tasks like image classification, language modeling, and fine-tuning transformers. With consistent updates, the most stable and recommended version is "0.8.0," which consolidates these features, delivering an optimized and reliable environment for both research and production use in modern AI applications.
When comparing Candle to other Rust-based deep learning crates, such as tch-rs and burn, Candle’s unique design philosophy and capabilities stand out. The tch-rs crate is a Rust binding for PyTorch, enabling Rust developers to leverage the mature PyTorch ecosystem. However, this approach makes tch-rs heavily dependent on the PyTorch backend, which can introduce additional runtime dependencies and limit its flexibility for Rust-first workflows. In contrast, Candle is written entirely in Rust, offering a native experience with no reliance on external frameworks. This makes it highly portable, lightweight, and better suited for environments where Rust’s safety and performance are critical.
On the other hand, burn positions itself as a modular deep learning framework emphasizing usability and flexibility, particularly for integrating with various computation backends like tch-rs or wgpu. While burn provides high-level abstractions for ease of use, it lacks the low-level optimizations and transformer-specific features that Candle excels at. Candle's focus on supporting transformer-based architectures, efficient tensor operations, and compatibility with large-scale language models makes it a more specialized and powerful option for tasks like NLP, computer vision, and large-scale generative models.
Candle’s potential for future development is immense. Its modular and extensible design is well-suited for incorporating next-generation machine learning techniques such as sparse transformers, efficient fine-tuning methods like LoRA (Low-Rank Adaptation), and multi-modal learning architectures. Developers can extend Candle to support additional use cases, such as reinforcement learning, graph neural networks, or even diffusion models for generative tasks. Furthermore, its compatibility with Rust’s asynchronous programming paradigm makes Candle a promising candidate for real-time inference and edge computing applications, where low-latency predictions are essential. As Hugging Face continues to expand Candle’s capabilities and the Rust ecosystem grows, Candle is poised to become a cornerstone library for deep learning, bridging the gap between research innovation and practical deployment in Rust-first environments.
The code below demonstrates the implementation of a neural network training pipeline for the MNIST dataset using the Rust-based candle library. The training process includes defining various models (Linear, Multi-Layer Perceptron, and Convolutional Neural Networks) and optimizing them using gradient descent methods to achieve high classification accuracy on handwritten digit images. The configuration for the training process, such as the model type, learning rate, number of epochs, and save/load paths for model weights, is hardcoded, making the program straightforward and focused on reproducibility.
[dependencies]
anyhow = "1.0"
candle-core = "0.8.0"
candle-examples = "0.8.0"
candle-hf-hub = "0.3.3"
candle-nn = "0.8.0"
candle-transformers = "0.8.0"
rand = "0.8.5"
use candle_core::{DType, Result, Tensor, D};
use candle_nn::{loss, ops, Conv2d, Linear, Module, ModuleT, Optimizer, VarBuilder, VarMap};
const IMAGE_DIM: usize = 784;
const LABELS: usize = 10;
fn linear_z(in_dim: usize, out_dim: usize, vs: VarBuilder) -> Result<Linear> {
let ws = vs.get_with_hints((out_dim, in_dim), "weight", candle_nn::init::ZERO)?;
let bs = vs.get_with_hints(out_dim, "bias", candle_nn::init::ZERO)?;
Ok(Linear::new(ws, Some(bs)))
}
// Define a trait for models
trait Model: Sized {
fn new(vs: VarBuilder) -> Result<Self>;
fn forward(&self, xs: &Tensor) -> Result<Tensor>;
}
// Linear model implementation
struct LinearModel {
linear: Linear,
}
impl Model for LinearModel {
fn new(vs: VarBuilder) -> Result<Self> {
let linear = linear_z(IMAGE_DIM, LABELS, vs)?;
Ok(Self { linear })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.linear.forward(xs)
}
}
// MLP model implementation
struct Mlp {
ln1: Linear,
ln2: Linear,
}
impl Model for Mlp {
fn new(vs: VarBuilder) -> Result<Self> {
let ln1 = candle_nn::linear(IMAGE_DIM, 100, vs.pp("ln1"))?;
let ln2 = candle_nn::linear(100, LABELS, vs.pp("ln2"))?;
Ok(Self { ln1, ln2 })
}
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.ln1.forward(xs)?;
let xs = xs.relu()?;
self.ln2.forward(&xs)
}
}
// Convolutional neural network (CNN) implementation
struct ConvNet {
conv1: Conv2d,
conv2: Conv2d,
fc1: Linear,
fc2: Linear,
dropout: candle_nn::Dropout,
}
impl ConvNet {
fn new(vs: VarBuilder) -> Result<Self> {
let conv1 = candle_nn::conv2d(1, 32, 5, Default::default(), vs.pp("c1"))?;
let conv2 = candle_nn::conv2d(32, 64, 5, Default::default(), vs.pp("c2"))?;
let fc1 = candle_nn::linear(1024, 1024, vs.pp("fc1"))?;
let fc2 = candle_nn::linear(1024, LABELS, vs.pp("fc2"))?;
let dropout = candle_nn::Dropout::new(0.5);
Ok(Self {
conv1,
conv2,
fc1,
fc2,
dropout,
})
}
fn forward(&self, xs: &Tensor, train: bool) -> Result<Tensor> {
let (b_sz, _img_dim) = xs.dims2()?;
let xs = xs
.reshape((b_sz, 1, 28, 28))?
.apply(&self.conv1)?
.max_pool2d(2)?
.apply(&self.conv2)?
.max_pool2d(2)?
.flatten_from(1)?
.apply(&self.fc1)?
.relu()?;
self.dropout.forward_t(&xs, train)?.apply(&self.fc2)
}
}
// Training arguments structure
struct TrainingArgs {
learning_rate: f64,
epochs: usize,
save: Option<String>,
load: Option<String>,
}
// Unified training loop for Linear and MLP models
fn training_loop<M: Model>(
m: candle_datasets::vision::Dataset,
args: &TrainingArgs,
) -> anyhow::Result<()> {
let dev = candle_core::Device::cuda_if_available(0)?;
let train_images = m.train_images.to_device(&dev)?;
let train_labels = m.train_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let test_images = m.test_images.to_device(&dev)?;
let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let mut varmap = VarMap::new();
let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);
let model = M::new(vs.clone())?;
if let Some(load) = &args.load {
println!("Loading weights from {load}");
varmap.load(load)?;
}
let mut sgd = candle_nn::SGD::new(varmap.all_vars(), args.learning_rate)?;
for epoch in 1..=args.epochs {
let logits = model.forward(&train_images)?;
let log_sm = ops::log_softmax(&logits, D::Minus1)?;
let loss = loss::nll(&log_sm, &train_labels)?;
sgd.backward_step(&loss)?;
let test_logits = model.forward(&test_images)?;
let sum_ok = test_logits
.argmax(D::Minus1)?
.eq(&test_labels)?
.to_dtype(DType::F32)?
.sum_all()?
.to_scalar::<f32>()?;
let test_accuracy = sum_ok / test_labels.dims1()? as f32;
println!(
"Epoch {epoch:4}: train loss {:8.5} test acc: {:5.2}%",
loss.to_scalar::<f32>()?,
100. * test_accuracy
);
}
if let Some(save) = &args.save {
println!("Saving trained weights in {save}");
varmap.save(save)?;
}
Ok(())
}
// Training loop for CNN model
fn training_loop_cnn(
m: candle_datasets::vision::Dataset,
args: &TrainingArgs,
) -> anyhow::Result<()> {
const BSIZE: usize = 64;
let dev = candle_core::Device::cuda_if_available(0)?;
let train_images = m.train_images.to_device(&dev)?;
let train_labels = m.train_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let test_images = m.test_images.to_device(&dev)?;
let test_labels = m.test_labels.to_dtype(DType::U32)?.to_device(&dev)?;
let mut varmap = VarMap::new();
let vs = VarBuilder::from_varmap(&varmap, DType::F32, &dev);
let model = ConvNet::new(vs.clone())?;
if let Some(load) = &args.load {
println!("Loading weights from {load}");
varmap.load(load)?;
}
let adamw_params = candle_nn::ParamsAdamW {
lr: args.learning_rate,
..Default::default()
};
let mut opt = candle_nn::AdamW::new(varmap.all_vars(), adamw_params)?;
let n_batches = train_images.dim(0)? / BSIZE;
for epoch in 1..=args.epochs {
let mut sum_loss = 0f32;
for batch_idx in 0..n_batches {
let train_images = train_images.narrow(0, batch_idx * BSIZE, BSIZE)?;
let train_labels = train_labels.narrow(0, batch_idx * BSIZE, BSIZE)?;
let logits = model.forward(&train_images, true)?;
let log_sm = ops::log_softmax(&logits, D::Minus1)?;
let loss = loss::nll(&log_sm, &train_labels)?;
opt.backward_step(&loss)?;
sum_loss += loss.to_vec0::<f32>()?;
}
let avg_loss = sum_loss / n_batches as f32;
let test_logits = model.forward(&test_images, false)?;
let sum_ok = test_logits
.argmax(D::Minus1)?
.eq(&test_labels)?
.to_dtype(DType::F32)?
.sum_all()?
.to_scalar::<f32>()?;
let test_accuracy = sum_ok / test_labels.dims1()? as f32;
println!(
"Epoch {epoch:4}: train loss {:8.5} test acc: {:5.2}%",
avg_loss,
100. * test_accuracy
);
}
if let Some(save) = &args.save {
println!("Saving trained weights in {save}");
varmap.save(save)?;
}
Ok(())
}
// Main function
fn main() -> anyhow::Result<()> {
let model_type = "Cnn"; // Change to "Linear", "Mlp", or "Cnn" as needed
let learning_rate = 0.001;
let epochs = 10;
let save_path = Some("trained_model.safetensors".to_string());
let load_path = None;
let dataset = candle_datasets::vision::mnist::load()?;
println!("train-images: {:?}", dataset.train_images.shape());
println!("train-labels: {:?}", dataset.train_labels.shape());
println!("test-images: {:?}", dataset.test_images.shape());
println!("test-labels: {:?}", dataset.test_labels.shape());
let training_args = TrainingArgs {
learning_rate,
epochs,
save: save_path,
load: load_path,
};
match model_type {
"Linear" => training_loop::<LinearModel>(dataset, &training_args),
"Mlp" => training_loop::<Mlp>(dataset, &training_args),
"Cnn" => training_loop_cnn(dataset, &training_args),
_ => panic!("Invalid model type"),
}
}
The program loads the MNIST dataset and initializes a neural network based on the selected model type. The dataset is split into training and testing sets, and the chosen model is trained iteratively over a predefined number of epochs. For each epoch, the program performs forward passes to compute predictions, calculates loss using negative log-likelihood, and backpropagates the gradients to update model weights using the AdamW optimizer. After training, the model's performance is evaluated on the test set by calculating accuracy. The program also supports saving the trained model's weights to a file for future use. By leveraging candle, the code efficiently handles tensor operations, model management, and training optimization, showcasing the potential of Rust in deep learning.
In conclusion, Candle combines the performance and safety benefits of Rust with the advanced features required for modern deep learning. Its transformer-specific optimizations, lightweight design, and extensibility position it as a compelling alternative to existing frameworks like tch-rs and burn. With its current capabilities and potential for growth, Candle stands as a transformative tool for building scalable, efficient, and cutting-edge AI applications, unlocking new possibilities for developers and researchers alike.
4.8. Conclusion
Chapter 4 equips you with the knowledge to effectively utilize and contribute to the Rust deep learning ecosystem. By mastering the use of tch-rs and candle in this DLVR book, you can build, optimize, and extend powerful AI models that leverage Rust’s strengths in performance and safety.
4.8.1. Further Learning with GenAI
These prompts are designed to deepen your understanding of the deep learning ecosystem in Rust, focusing on the capabilities and applications of the tch-rs and candle crates.
Discuss the advantages of using Rust for deep learning compared to other programming languages like Python and C++. Explore how Rust’s memory safety, strong type system, and concurrency features provide a robust foundation for deep learning. Analyze how these characteristics enhance the reliability and performance of deep learning frameworks like
tch-rsandcandlewhen compared to the dynamic nature of Python or the manual memory management of C++.Examine the design and architecture of the
tch-rsandcandlecrates. Compare the integration oftch-rswith PyTorch's C++ backend to the native Rust-first approach ofcandle. Highlight the key architectural differences, includingtch-rs's reliance on PyTorch versuscandle’s focus on lightweight, modular design for transformers and deep learning.Analyze the role of tensor operations in deep learning and how
tch-rsandcandlehandle them in Rust. Discuss the performance implications of Rust for tensor manipulation, comparing the PyTorch-backed optimizations intch-rswith the fully native tensor operations incandle. Evaluate howcandle’s Rust-centric design enhances portability and minimizes dependencies.Evaluate the automatic differentiation capabilities of
tch-rsandcandle. Compare the backpropagation implementations in both crates, highlighting howtch-rsleverages PyTorch's autograd system and howcandleachieves gradient computation natively. Discuss the challenges and benefits of implementing differentiation in Rust’s ecosystem.Discuss the modularity and flexibility of the
candlecrate for deep learning architectures. Examine howcandleallows for building and extending custom architectures, particularly for transformers and large models. Compare its flexibility withtch-rs, emphasizingcandle’s Rust-native advantages and suitability for experimentation and deployment.Explore the process of building and training a neural network using
candle. Outline the key steps in defining, training, and fine-tuning a model usingcandle. Analyze how Rust’s ownership model, type safety, and concurrency contribute to efficient and reliable code in deep learning projects.Compare the performance of deep learning models built with
tch-rsandcandle. Identify the key factors that influence performance, such as dependency management, GPU support, and tensor operation optimizations. Evaluate scenarios wherecandle’s Rust-native design outperforms the PyTorch-backedtch-rs.Investigate the integration of
tch-rsandcandlewith other Rust crates and external libraries. Discuss how the Rust ecosystem enables seamless integration with tools for data processing, visualization, or serialization. Highlight best practices for extending the functionality of these frameworks to enhance deep learning workflows.Examine the potential for contributing to the
tch-rsandcandlecrates. Identify key areas for improvement or extension, such as better support for distributed training, advanced transformers, or new optimization techniques. Discuss how contributors can align their work with the broader Rust deep learning community.Discuss the challenges of deploying Rust-based deep learning models in production environments. Compare how
tch-rsandcandlehandle deployment workflows, including model serialization, inference optimizations, and cross-platform support. Provide recommendations for ensuring reliability and performance in real-world applications.Analyze the role of GPU acceleration in Rust deep learning frameworks. Compare how
tch-rsandcandleutilize GPU resources, focusing on ease of setup, compatibility, and performance. Discuss the future of GPU acceleration in Rust-based deep learning, especially for transformer models.Explore the process of debugging and profiling deep learning models in Rust. Highlight available tools and techniques for identifying performance bottlenecks and memory issues in
tch-rsandcandle. Discuss how Rust’s tooling ecosystem contributes to efficient debugging and optimization.Evaluate the documentation and community support for
tch-rsandcandle. Assess the quality and availability of learning resources, examples, and community engagement for these frameworks. Discuss improvements that could make Rust-based deep learning more accessible to new developers.Discuss the potential for hybrid approaches in Rust deep learning, combining
tch-rswithcandle. Explore scenarios where the two frameworks could complement each other, leveraging the PyTorch ecosystem oftch-rsand the Rust-native design ofcandlefor specific AI tasks.Analyze the impact of Rust’s ownership model on deep learning code structure and performance. Discuss how
tch-rsandcandleimplement ownership and borrowing principles to ensure safety while maintaining high performance in neural network training and inference.Explore the role of serialization and deserialization in Rust-based deep learning models. Examine how
tch-rsandcandlehandle model saving and loading, focusing on efficiency, compatibility, and cross-platform support. Discuss the challenges of ensuring seamless model portability across environments.Investigate the use of advanced optimizers in Rust deep learning frameworks. Compare how
tch-rsandcandleimplement popular optimizers like Adam, RMSprop, and custom strategies. Analyze the impact of these optimizers on training speed and model convergence.Examine the scalability of Rust deep learning models. Discuss how
tch-rsandcandleenable scaling across multiple devices or distributed systems. Provide best practices for managing large-scale deployments using Rust-based frameworks.Discuss the potential for Rust in research-focused deep learning projects. Analyze how
tch-rsandcandlesupport experimentation, innovation, and rapid prototyping for cutting-edge AI research. Highlight the advantages of Rust in ensuring reproducibility and performance for academic projects.Analyze the future directions of deep learning in Rust. Examine trends and advancements in Rust’s machine learning ecosystem, predicting how
tch-rsandcandlemay evolve to address emerging AI challenges. Discuss opportunities for Rust to establish itself as a leading language for deep learning.
Let these prompts inspire you to push the boundaries of what you can achieve with Rust in the field of AI.
4.8.2. Hands On Practices
These exercises challenge you to apply advanced techniques in Rust, focusing on building, optimizing, and extending deep learning models using the tch-rs and candle crates.
Exercise 4.1: Implementing a Custom Neural Network in tch-rs
Task: Build a custom neural network architecture in Rust using the
tch-rscrate, focusing on optimizing tensor operations and leveraging automatic differentiation. Implement advanced features such as custom layers or activation functions.Challenge: Train your neural network on a large-scale dataset and fine-tune the model for high accuracy and performance. Compare the results with equivalent models built in other frameworks, analyzing the trade-offs in terms of training speed, memory usage, and code complexity.
Exercise 4.2: Developing a Modular Deep Learning Framework with candle
Task: Create a modular deep learning model in Rust using the
candlecrate, implementing a complex architecture such as a GAN or Transformer. Focus on the flexibility and reusability of the modules, allowing for easy experimentation and customization.Challenge: Extend your framework by integrating additional functionalities, such as custom optimizers or data augmentation techniques. Evaluate the performance of your model on different tasks, comparing it with similar implementations in other deep learning frameworks.
Exercise 4.3: Comparative Analysis of tch-rs and candle
Task: Implement the same deep learning model using both
tch-rsandcandle, comparing the two frameworks in terms of ease of use, performance, and scalability. Focus on training efficiency, model accuracy, and resource management.Challenge: Optimize both implementations for a specific task, such as image classification or sequence prediction, and analyze the strengths and weaknesses of each framework. Provide a detailed report on the trade-offs between using
tch-rsandcandlefor different types of deep learning projects.
Exercise 4.4: Extending the candle Crate with Custom Features
Task: Identify an area of improvement or extension in the
candlecrate, such as adding a new optimizer, regularization technique, or layer type. Implement your contribution and integrate it into the existing framework.Challenge: Test your new feature on a deep learning model and evaluate its impact on training performance and model accuracy. Submit your contribution to the
candlerepository as a pull request, following best practices for open-source development.
Exercise 4.5: Deploying a Rust-Based Deep Learning Model
Task: Deploy a deep learning model built with
tch-rsorcandlein a production environment, focusing on ensuring reliability, scalability, and performance. Implement necessary features such as model serialization, error handling, and performance monitoring.Challenge: Scale your deployment to handle real-world data and traffic, optimizing the model for latency and throughput. Compare the performance of your Rust-based deployment with equivalent models in other languages, analyzing the trade-offs in terms of deployment complexity, resource usage, and response times.
By completing these challenging tasks, you will develop the skills needed to tackle complex AI projects, ensuring you are well-prepared for real-world applications in deep learning.
Comments